Machine Learning/scikit-learn
결정 트리 실습 - 사용자 행동 인식 데이터 분류 예제
ISLA!
2023. 8. 21. 19:21

🧑🏻💻 예제 설명
- 스마트폰 센서를 장착한 30명의 행동데이터를 수집
- 결정 트리를 이용해 어떠한 동작인지 예측
데이터 불러오기 : feature.txt 파일 로드
피처 인덱스와 피처명을 가지고 있으므로 이를 DataFrame으로 로딩하여, 피처 명칭 확인
import pandas as pd
DATA_PATH = '/content/drive/MyDrive/data'
feature_name_df = pd.read_csv(DATA_PATH + '/human_activity/features.txt',sep='\s+',
header=None,names=['column_index','column_name'])
feature_name_df.head(1)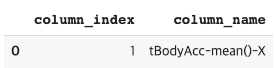
피처명 index 제거 후, 피처만 따로 저장
- 피처명 : 인체의 움직임과 관련된 속성의 평균/표준편차가 x, y, z 축 값으로 되어 있음
- 그런데, 피처명의 중복이 있어 이를 처리해야 함
feature_name = feature_name_df.iloc[:, 1].values.tolist()
feature_name[:10]
중복된 피처명 확인
- 아래 코드를 보면 중복 피쳐가 42개나 되는 것을 알 수 있다
- 간단히 중복 피쳐 5개의 데이터만 확인해보면 아래와 같다
- 중복 피쳐를 처리하기 위해 함수를 작성해본다 : 원본 피처명에 중복 피쳐명을 _1, _2를 붙여서 변경
feature_dup_df = feature_name_df.groupby('column_name').count()
print(feature_dup_df[feature_dup_df['column_index'] > 1].count())
feature_dup_df[feature_dup_df['column_index'] > 1].head()
중복된 피처명 처리 함수
- 기존 데이터 프레임을 받아, 중복 피쳐명을 처리하는 함수 정의
- feature_dup_df = 기존 데이터프레임에 column_name으로 그루핑하여 각 컬럼별로 누적 개수를 센다 >> dup_cut 로 저장
- feature_dup_df 의 인덱스 리셋
- new_feature_dup_df = 기존 데이터프레임과 feature_dup_df를 연결 (아우터 조인)
- new_feature_dup_df['column_name'] = column_name과 dup_cnt 열만 따로 빼서 람다 함수 적용
- dup_cnt 값이 1보다 크면(즉 중복 컬럼이면) column_name 과 dup_cnt 값을 _로 연결하기
- 1보다 크지 않으면 (중복 컬럼이 아니면) 그대로 column_name 반환
- new_feature_dup_df의 인덱스 컬럼 삭제
- new_feature_dup_df 반환
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data = old_feature_name_df.groupby('column_name').cumcount(), columns = ['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(), feature_dup_df, how = 'outer')
# 중복 feature 명에 대해 원본 feature_1, _2 추가
new_feature_name_df['column_name'] = new_feature_name_df[['column_name', 'dup_cnt']].apply(lambda x : x[0] + '_' + str(x[1]) if x[1] > 0 else x[0], axis = 1)
new_feature_name_df = new_feature_name_df.drop(['index'], axis = 1)
return new_feature_name_df
function_test = get_new_feature_name_df(feature_name_df)
function_test.sample(5)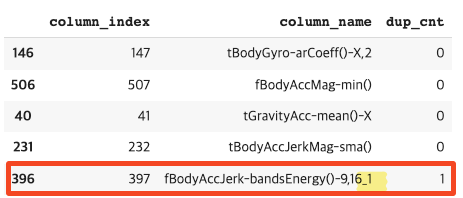
train 데이터와 test 데이터 처리 : 함수
- train과 test 데이터를 불러오기
- 앞서 정의한 중복 피쳐 처리 함수 적용
- 컬럼명을 리스트로 추출
- 학습 데이터와 테스트 데이터 셋 설정
import pandas as pd
def get_human_dataset( ):
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
DATA_PATH = '/content/drive/MyDrive/data'
feature_name_df = pd.read_csv(DATA_PATH + '/human_activity/features.txt',sep='\s+',
header=None,names=['column_index','column_name'])
# 중복된 피처명을 수정하는 get_new_feature_name_df()를 이용, 신규 피처명 DataFrame생성.
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용
X_train = pd.read_csv(DATA_PATH + '/human_activity/train/X_train.txt',sep='\s+', names=feature_name )
X_test = pd.read_csv(DATA_PATH + '/human_activity/test/X_test.txt',sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여
y_train = pd.read_csv(DATA_PATH + '/human_activity/train/y_train.txt',sep='\s+',header=None,names=['action'])
y_test = pd.read_csv(DATA_PATH + '/human_activity/test/y_test.txt',sep='\s+',header=None,names=['action'])
# 로드된 학습/테스트용 DataFrame을 모두 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()
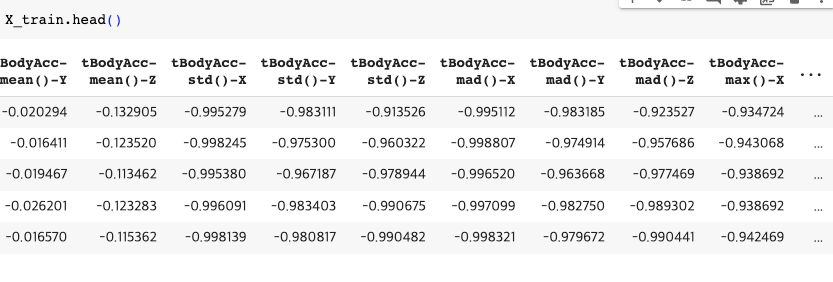
train 데이터셋 확인
- 약 7000개의 레코드, 561개의 피쳐(컬럼) 가지고 있음
- 피쳐가 전부 실수형(숫자)이므로, 별도 카테고리 인코딩 필요 없음

label(결과) 데이터셋 확인
- 1부터 6까지 여섯개의 값이 있으며 비교적 고르게 분포되어 있음

DecisionTreeClassifier 로 동작 예측 분류
- 기본적으로 하이퍼파라미터를 손대지 않고 예측한 결과의 정확도와 파라미터를 출력해보자
- 정확도는 약 85.48%
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 예제 반복 시 마다 동일한 예측 결과 도출을 위해 random_state 설정
dt_clf = DecisionTreeClassifier(random_state=156)
dt_clf.fit(X_train , y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test , pred)
print('결정 트리 예측 정확도: {0:.4f}'.format(accuracy))
# DecisionTreeClassifier의 하이퍼 파라미터 추출
print('DecisionTreeClassifier 기본 하이퍼 파라미터:\n', dt_clf.get_params())결과
결정 트리 예측 정확도: 0.8548
DecisionTreeClassifier 기본 하이퍼 파라미터: {'ccp_alpha': 0.0, 'class_weight': None, 'criterion': 'gini', 'max_depth': None, 'max_features': None, 'max_leaf_nodes': None, 'min_impurity_decrease': 0.0, 'min_samples_leaf': 1, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'random_state': 156, 'splitter': 'best'}
GridSearchCV 로 최적의 파라미터 찾기
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [6, 16, 24],
'min_samples_split': [16]
}
grid_cv = GridSearchCV(dt_clf, param_grid = params, scoring = 'accuracy', cv = 5, verbose = 1)
grid_cv.fit(X_train, y_train)결과 확인
- 정확도 수치가 84.86% 까지 올라감
print('정확도 수치', grid_cv.best_score_)
print('최적 파라미터', grid_cv.best_params_)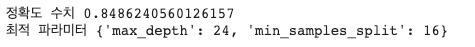
728x90