Machine Learning/scikit-learn
[데이터 분할] 학습 세트와 검증 세트 분할 : train_test_split()
ISLA!
2023. 8. 14. 22:27

✅ scikit-learn의 train_test_split() 함수를 사용하여 데이터를 학습 세트와 검증 세트로 분할
- train_test_split() 함수는 데이터를 학습에 사용할 부분과 모델을 평가하는 데 사용할 부분으로 분할하기 위해 사용
- 데이터의 일부를 검증 세트로 분리하여 학습한 모델의 성능을 평가함으로써, 과적합을 방지하고 일반화 성능을 확인
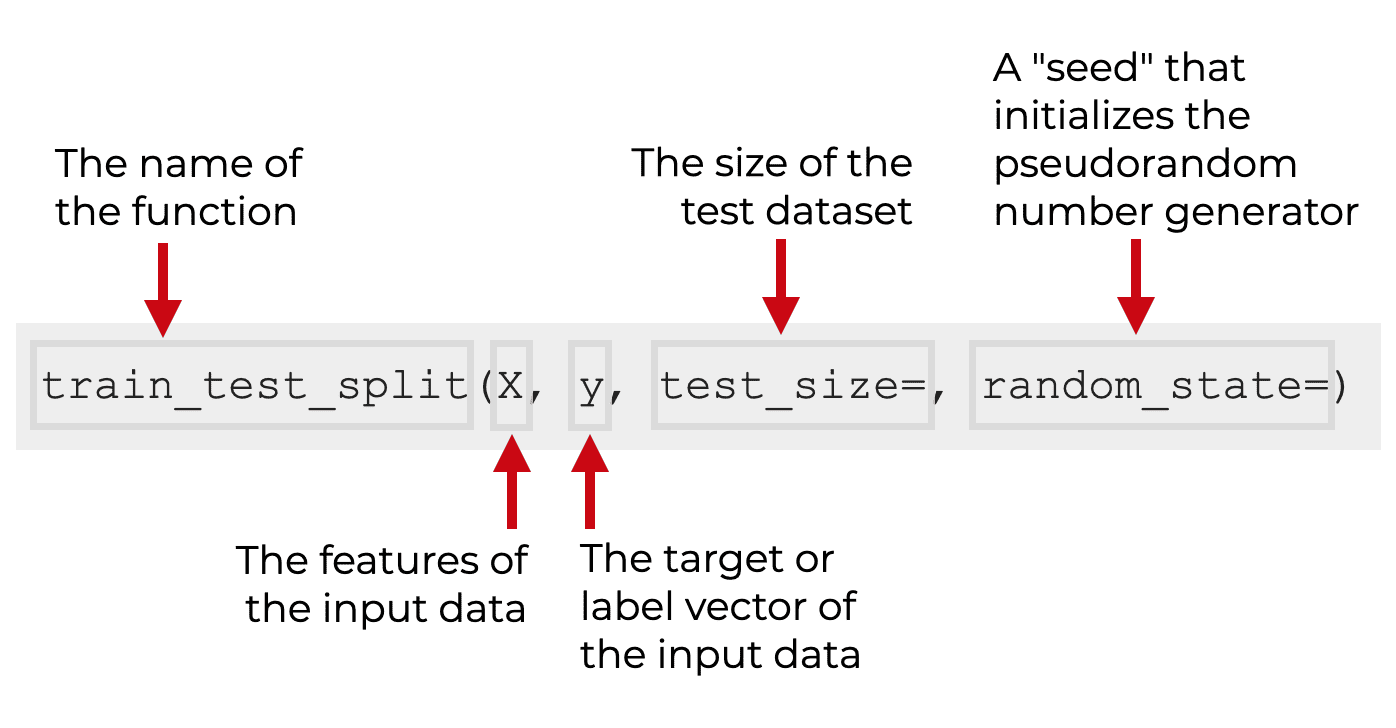
✅ 사용법
1. sklearn.model_selection 모듈에서 train_test_split 을 로드
2. train_test_split() 함수를 호출하여 train_x, train_y 데이터를 x_train, x_valid, y_train, y_valid로 분할
from sklearn.model_selection import train_test_split
x_train, x_valid, y_train, y_valid = train_test_split(train_x, train_y, test_size = 0.3, random_state = 42) 👉 x_train, x_valid, y_train, y_valid 데이터는 순서대로
: 학습 세트의 독립 변수, 검증 세트의 독립 변수, 학습 세트의 종속 변수, 검증 세트의 종속 변수를 나타냄
👉 파라미터
- 첫 번째 파라미터 : 피처 데이터 세트(x)
- 두 번째 파라미터 : 레이블 데이터 세트(y)
- test_size : 검증 세트의 크기, 전체 데이터에서 얼마나의 비율을 검증 세트로 할당할지 결정
- 디폴트는 0.25
- random_state : 데이터를 분할할 때 셔플링을 제어하기 위한 시드 값
- 학습/예측을 수행할 때마다 동일한 데이터 세트로 분리하기 위함
728x90