Programming Basics
[웹 크롤링] 네이버 연합뉴스의 타이틀 크롤링
ISLA!
2023. 8. 4. 23:11
네이버 뉴스 페이지에서 헤드라인만 크롤링하기
이번엔 웹에서 원하는 데이터만 뽑아 추출하는 것을 시작해보자!
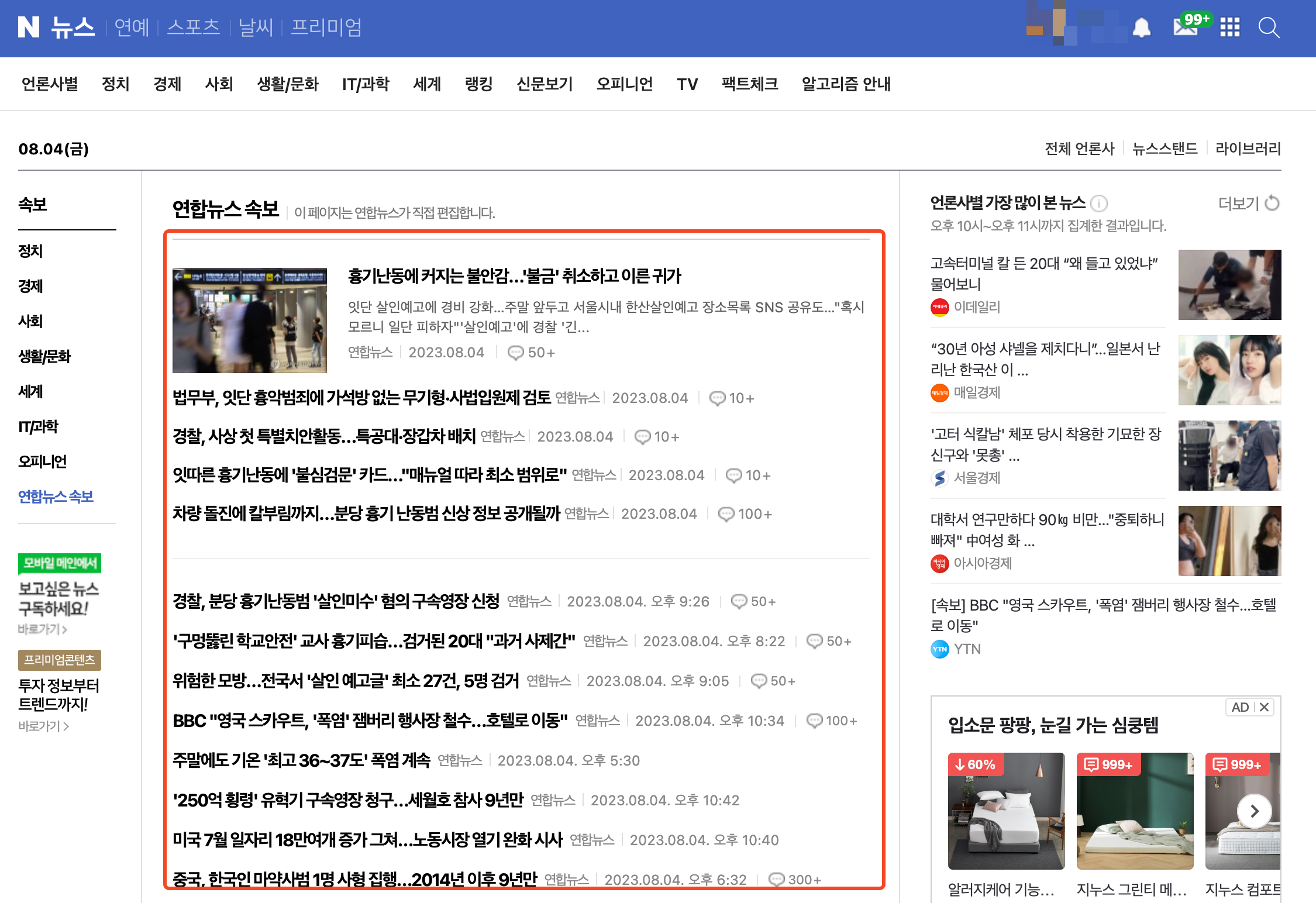
가장 먼저 네이버 뉴스 페이지의 헤드라인을 크롤링해본다. 크롤링을 원하는 부분은 다음과 같다.
🚴♂️ Requests & Beautifulsoup 라이브러리 사용
- Requests 는 API 호출시에도 사용되며, 기본적으로 웹사이트 크롤링에 많이 쓰임.
- 샘플 코드 : url 로부터 상태코드를 받는 과정
import requests
from bs4 import BeautifulSoup
url = "https://www.naver.com"
#요청 url 변수에 담긴 url의 html 문서 정보 출력
req = requests.get(url)
print(req.status_code)
1. 크롤링하고 싶은 부분의 html 확인
- 마우스 우클릭하고 웹페이지의 html 의 구성을 확인한다.
- 어떤 요소를 크롤링하고 싶은지를 구체적으로 확인하는 과정이다.
- 여기서는 연합뉴스 페이지의 헤드라인만 가져오고 싶기 때문에, 해당 부분을 확인한다
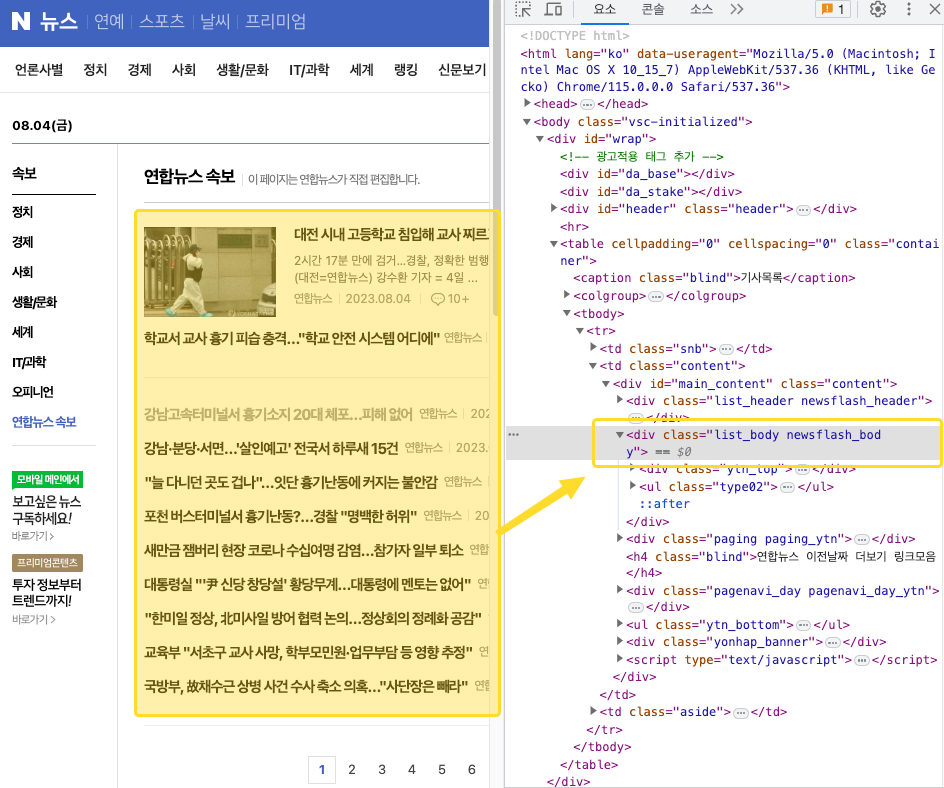
2. 크롤링하고 싶은 부분의 html 확인
- 이제 크롤링 코드를 작성해보자.
- requests 라이브러리와 BeautifulSoup 라이브러리가를 import 한다.
- main 함수 :
- 크롤링 하고 싶은 url 작성
- custom_header
- user-agent : 크롤러가 아님을 숨기기 위해, 네이버 서버에 사용자정보 전달
- 크롤러가 인간의 웹 브라우저처럼 행동하도록 하여 사이트 접근을 용이하게 하는데 사용됨
- requests의 get 메서드를 사용하여 "http get" 요청을 보내는데, 이를 req 변수에 저장 >> 서버로부터 데이터 가져옴
- req.text : requests.get() 함수로 보낸 HTTP GET 요청에 대한 응답 데이터를 가져옴(문자열로)
- "html.parser": BeautifulSoup 객체를 생성할 때 사용되는 파서(parser)의 종류를 지정
- crawler 함수 :
- soup 객체에 저장된 내용 중, div 태그의 class가 list_body인 부분만 가져와 div 객체에 저장
- result 라는 빈 리스트 생성
- div 내용 중, a 태그에 담긴 내용만 가져와, result 리스트에 저장
import requests
from bs4 import BeautifulSoup
def crawler(soup):
#print(soup) >> 작동 확인 완료
div = soup.find("div", class_ = "list_body")
result = []
for a in div.find_all("a"): #find_all의 반환값 형태는 리스트
result.append(a.get_text())
return result
def main():
url = "https://news.naver.com/main/list.naver?mode=LPOD&mid=sec&sid1=001&sid2=140&oid=001&isYeonhapFlash=Y"
#연합뉴스 제목타이틀 가져오기
custom_header = {
'referer' : 'https://www.naver.com/',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
url = "https://news.naver.com/main/list.nhn?mode=LPOD&mid=sec&sid1=001&sid2=140&oid=001&isYeonhapFlash=Y"
req = requests.get(url, headers = custom_header)
#print(req.status_code)
soup = BeautifulSoup(req.text, "html.parser")
result = crawler(soup)
print(result)
if __name__ == "__main__":
main()
📃 결과 확인

728x90