Programming Basics
[Scrapy 크롤링] Worldometer에서 나라이름 크롤링
ISLA!
2023. 8. 8. 17:29
scrapy 설치 후, import
!pip install scrapyimport scrapy
프로젝트 하나 만들기
$ scrapy startproject multiCam_tutorial👉 폴더 생성 확인

▶︎ 아래 명령어를 입력하여 사용할 수 있는 메서드 확인
$scrapy
⚡️ 예제 : Worldometer 웹사이트에서 인구 관련 데이터 크롤링해보기
아래 사이트를 크롤링할 예정
Population by Country (2023) - Worldometer
Countries in the world by population (2023) This list includes both countries and dependent territories. Data based on the latest United Nations Population Division estimates. Click on the name of the country or dependency for current estimates (live popul
www.worldometers.info
👉 터미널에 다음을 입력
$ scrapy genspider worldometer https://www.worldometers.info/world-population/population-by-country/👉 파일 생성 확인 : worldometer.py
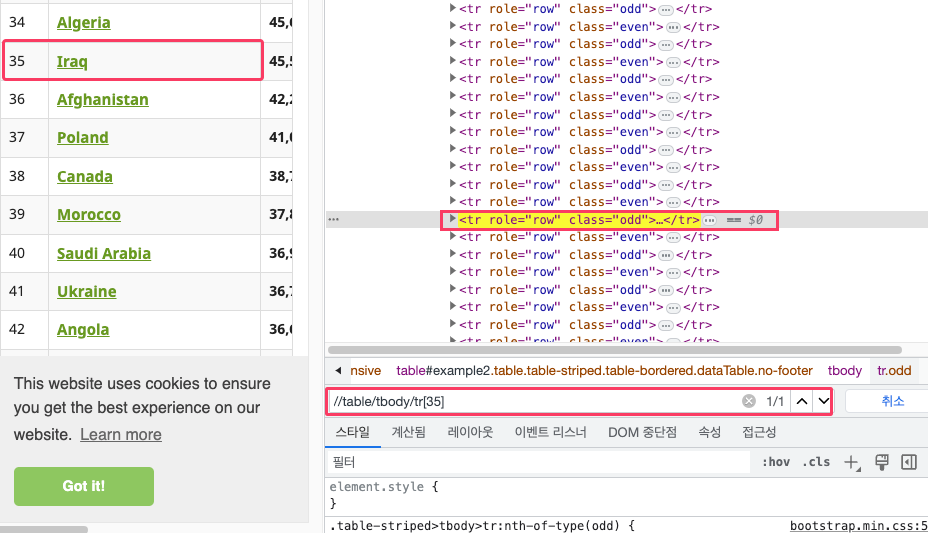
xPath를 사용해서 크롤링을 원하는 부분 찾기
- 위 사이트에 접속 > 마우스 우클릭 > 검사 > 요소에 들어가서
- ctrl + f 를 누르면 xpath 입력가능한 검색창이 나타난다
- 해당 검색창에 xpath 를 입력하면 원하는 부분을 특정해서 살펴볼 수 있다.

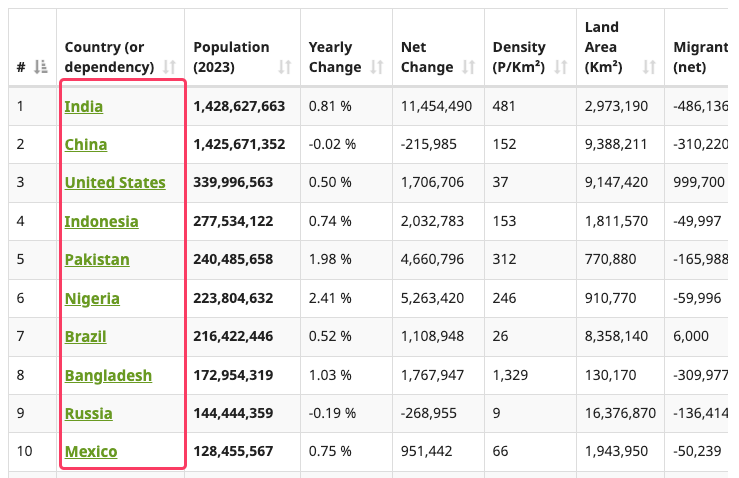
[활동1] 표의 국가명 뽑아보기
>> 아래 캡쳐에서 보이는 표의 country 컬럼의 값들만 크롤링해보자.
>> 코드 작성
- worldometer.py를 열면, 기본적인 템플릿이 나온다
- def parse 이하부터 작성한다
- xpath를 사용해, 웹사이트에서 '국가명' 부분의 경로를 작성해준다
- .get() 으로 내용을 리스트 형식으로 가져온다
- yield { } 로 크롤링한 데이터를 출력한다
import scrapy
class WorldometerSpider(scrapy.Spider):
name = "worldometer" #spider의 이름
allowed_domains = ["www.worldometers.info"] #크롤링을 허용할 도메인
start_urls = ["https://www.worldometers.info/world-population/population-by-country/"]
# 크롤링을 시작할 url 리스트
def parse(self, response): #parse 메서드는 크롤링된 웹페이지의 응답을 처리
title = response.xpath('//hi/text()').get() #하나만 가져옴
# 'a'요소를 추출 for each country
yield {
'title' : title
}
pass👉 scrapy crawl worldometer 를 터미널에 입력하여 결과 확인
>> title : 국가명이 쭉 나타나면 성공
728x90