
✅ 피처 스케일링이란?
서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업으로, 두 가지가 있다
1. 표준화
2. 정규화
✅ 표준화란?
- 데이터의 피처 각각이 평균이 0이고 분산이 1인 가우시안 정규분포를 가진 값으로 변환하는 것
- 변환식은 다음과 같다.

✅ 정규화란?
- 일반적으로 정규화는 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 개념이다.
- 예를 들어, 피처A는 거리를 나타내고, 피처 B는 금액을 나타내며 두 피처 값의 범위가 다를 때, 이 변수들을 모두 동일한 크기 단위로 비교하기 위해 값을 모두 최소 0 ~ 최대 1의 값으로 변환하는 것이다.
- 즉, 개별 데이터의 크기를 모두 똑같은 단위로 변경하는 것이다.
- 변환식은 다음과 같다.(선형대수의 정규화)
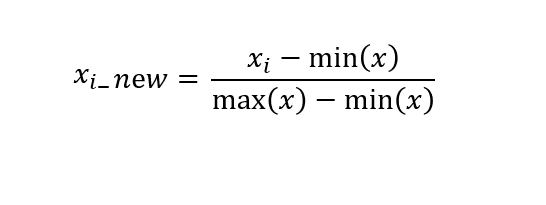
- 단, 사이킷런에서의 정규화 모듈은 벡터 정규화를 따른다.
✅ 표준화를 지원하는 사이킷런 클래스 : StandardScaler
- 다시 복기해보면, 표준화는 평균이 0 이고 분산이 1인 값으로 피처를 변환해준다.
- 사이킷런에서 구현한 RBF 커널을 이용하느 서포트 벡터 머신이나 선형회귀, 로지스틱 회귀는 데이터가 가우시안 분포를 가지고 있다고 가정하고 구현됐기 때문에, 사전에 표준화를 적용하는 것은 예측 성능 향상에 중요한 요소가 된다.
- 예제를 통해 확인해보자
👉 표준화 전 : 평균과 분산값을 먼저 확인해보자
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
iris_data = iris.data
iris_df = pd.DataFrame(data = iris_data, columns = iris.feature_names)
print('feature 들의 평균값')
print(iris_df.mean())
print('\nfeature 들의 분산값')
print(iris_df.var())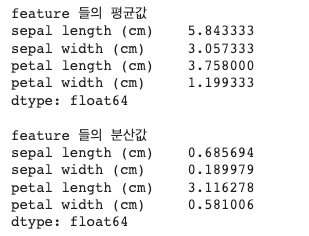
👉 표준화 후 : 평균과 분산값 변화
- 모든 칼럼 값의 평균이 0에 아주 가까운 값으로, 분산은 1에 아주 가까운 값으로 변환됐음
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
print('feature 들의 평균값')
print(iris_df_scaled.mean())
print('\nfeature 들의 분산값')
print(iris_df_scaled.var())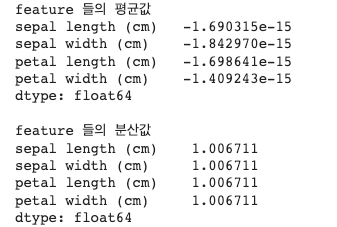
✅ MinMaxScaler
- 데이터 값을 0과 1 사이의 범위 값으로 변환
- 음수 값이 있으면 -1 에서 1 사이 값으로 변환
- 데이터의 분포가 가우시안 분포가 아닌 경우에 Min, Max Scale 을 적용해 볼 수 있음
from sklearn.preprocessing import MinMaxScaler
# 객체 생성
scaler = MinMaxScaler()
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns = iris.feature_names)
print('feature들의 최솟값')
print(iris_df_scaled.min())
print('\nfeature들의 최댓값')
print(iris_df_scaled.max())
✅ fit(), transform() 수행시 유의할 점
- 가능하다면 전체 데이터의 스케일링 변환 뒤 =>> 학습과 테스트 데이터로 분리
- 위 상황이 여의치 않다면 테스트 데이터 변환 시에는 fit()이나 fit_transform()을 적용하지 않고!!
학습 데이터로 fit() 된 Scaler 객체를 이용해 transform()으로 변환
👉 머신러닝 모델은 학습 데이터를 기반으로 학습되기 때문에 반드시 테스트 데이터는 학습 데이터의 스케일링 기준에 따라야 한다!
728x90
'Machine Learning' 카테고리의 다른 글
| [회귀] 회귀 모델의 R2(결정계수)를 올리는 방법 (0) | 2024.02.21 |
|---|---|
| 결정계수(coefficient of determination ) (0) | 2023.09.01 |
| statsmodels 회귀분석 (0) | 2023.09.01 |
| object 로 된 숫자를 수치(정수)형으로 바꾸기 (0) | 2023.08.31 |
| One-Hot Encoding(원-핫 인코딩) (0) | 2023.08.31 |



