벅스 뮤직에서 차트 탑 100 노래의 제목 가져오기
1. html 구조보기
- 마우스 우클릭 > 검사 > 요소
- 탑100 노래 제목이 어떤 구조 안에 있는지 살펴보기

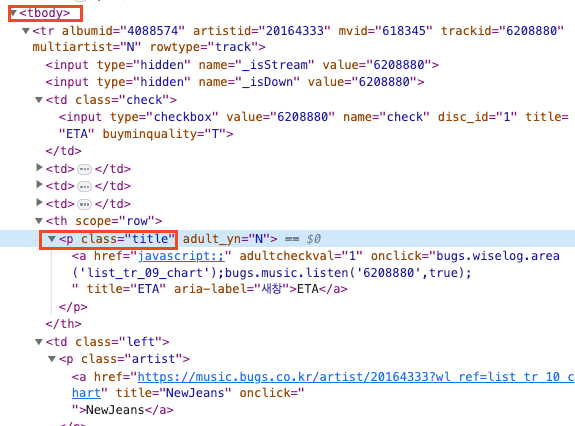
2. 크롤링 코드 작성
import requests
from bs4 import BeautifulSoup
import pandas as pd
def creatDf(result_list):
result_pf = pd.DataFrame({'title': result_list})
return result_pf
def crawler(soup):
tbody = soup.find("tbody")
result = []
for p in tbody.find_all("p", class_="title"):
result.append(p.get_text().replace('\n', ""))
return result
def main():
#bugs 음악 top100위 제목타이틀 리스트에 담기
custom_header = {
'referer' : 'https://music.bugs.co.kr/',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
url = "https://music.bugs.co.kr/chart"
req = requests.get(url, headers = custom_header)
soup = BeautifulSoup(req.text, "html.parser")
result = crawler(soup)
df = creatDf(result)
print(df)
df.to_csv("result.csv", index=False)
if __name__ == "__main__":
main()
📃 결과 확인

아래에서 Requests library의 공식 문서를 확인
Requests: HTTP for Humans™ — Requests 2.31.0 documentation
Requests: HTTP for Humans™ Release v2.31.0. (Installation) Requests is an elegant and simple HTTP library for Python, built for human beings. Behold, the power of Requests: >>> r = requests.get('https://api.github.com/user', auth=('user', 'pass')) >>> r.
requests.readthedocs.io
728x90
'Programming Basics' 카테고리의 다른 글
| [웹 크롤링] 주식 일별 시세를 데이터프레임으로 저장하기 (0) | 2023.08.05 |
|---|---|
| [웹 크롤링] 네이버 증권에서 '종목코드', '상장회사', '주가' 크롤링하기 (0) | 2023.08.04 |
| [웹 크롤링] 네이버 연합뉴스의 타이틀 크롤링 (0) | 2023.08.04 |
| [웹 크롤링] 로컬 html 파일에서 데이터 가져오기 (0) | 2023.08.04 |
| 쿠키와 세션 (0) | 2023.08.01 |



