
🧐 잘 모르는 분야의 데이터를 처음 받아들었다면?
👉 데이터에 얼마나 익숙한지와 무관하게 일정한 루틴에 따라 데이터를 이해하는 것이 중요하다
- 데이터의 행이 어떻게 고유하게 식별되는가? (분석단위가 무엇인가?)
- 데이터셋의 행과 열은 몇 개인가
- 주요 범주형 변수(categorical variable)는 무엇이고 값의 빈도는 어떠한가?
- 중요한 연속변수(continuous variable)가 어떻게 분포하는가?
- 변수들은 서로 어떻게 연관되는가?
- 이상치와 누락값은 어떻게 분포하는가?
데이터 불러오고 확인하기
# 인덱스 설정(행의 고유값)
df.set_index('personid', inplace = True)
df.head()
# 행과 열 크기 확인
df.shape
# 인덱스 고유값 개수 확인
df.index.nunique()
# null값 확인
df.info()열 선택, 정돈하기
- 데이터를 정제하거나 탐색적 혹은 통계적 분석을 할 때는 당면한 이슈나 분석에 관련된 변수에 집중하는 것이 좋다
- 열을 실체적 혹은 통계적 관계에 따라 그룹화하거나 한 번에 한 열씩 선택해 조사하는 것이 중요하다
- 직관을 얻으려면 한 번에 다루는 데이터 양이 인식범위를 넘지 않아야 함!
[object를 category로 바꾸기]
# 객체(object) 자료형을 선택 -> category 자료형으로 바꾸기
nls97.loc[:, nls97.dtypes == 'object'] = nls97.select_dtypes(['object']).apply(lambda x: x.astype('category'))
[컬럼명 필터링하여 복수 열 선택하기]
# 컬럼명 필터링
analysiswork = df.filter(like="weeksworked")
▶︎ (참고) filter 연산자는 정규식을 취할 수도 있음 :
# 예시 : 이름에 income이 포함된 열을 반환
df.filter(regex = 'income')
[자료형을 기준으로 열 선택하기]
# 범주형/숫자형인 열 모두 선택 =>> 자료형을 기준으로 열 선택하려면 select_dtypes()
analysiscats = nls97.select_dtypes(include = ['category'])
analysisnums = nls97.select_dtypes(include = ['number'])
[조건을 기준으로 행과 열 선택하기]
df.loc[(df.nightlyhrssleep <= 4) & (df.childathome >= 3), ['nightlyhrssleep', 'childathome']]
범주형 변수 빈도 생성하기
- 논리적으로 범주형이지만 객체 자료형으로 된 데이터를 다룰 때에는 범주형으로 변환하는 것이 타당함
- value_counts() 메서드를 활용하는 다양한 예는 아래와 같다.
- 빈도와 비율 표시, 조건을 준 열에서 비율 표시 등
df.loc[:, df.dtypes == 'object'] = df.select_dtypes(['object']).apply(lambda x : x.astype('category'))
# 빈도순 정렬 해제
df.maritalstatus.value_counts(sort = False)
# 빈도를 비율로
df.maritalstatus.value_counts(sort = False, normalize = True)
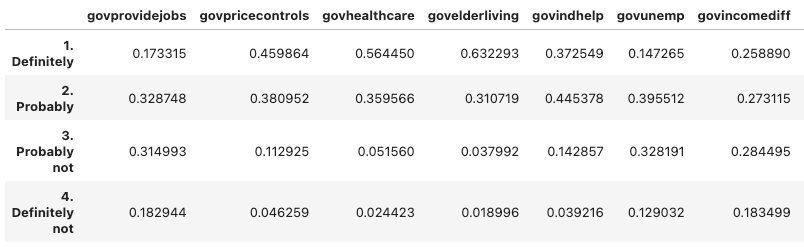
# 정부 책임 관련 열 전체를 비율로 표시
df.filter(like='gov').apply(pd.value_counts, normalize = True)
# 정부 책임 관련 열에서 기혼자만 찾기
df[df.maritalstatus == 'Married'].filter(like='gov').apply(pd.value_counts, normalize = True)
연속형 변수의 요약통계 살펴보기
- 중심경향(central tendency), 퍼진 정도(spread), 왜도(skewness)를 살펴보고
- 이상값과 예상치 못한 값(unexpected value)을 식별하는데도 활용한다.
[describe() 확인 👉 평균과 중앙값의 차이가 매우 크면 위험 신호]
covidtotals.describe()

[백분위수 확인]
- 아래 예시에서는 확진자 수와 사망자 수의 90번째 백분위수와 100번째 백분위수 차이가 상당이 큼
- 데이터가 정규분포를 따르지 않음을 나타내는 좋은 지표 👉 추후 진행할 통계적 검정에 중요하므로 유의!
- 총 사망자 수 가운데 10%가 넘는 값이 0이라는 점도 통계적 검정에 중요하므로 유의
totvars = ['location', 'total_cases', 'total_deaths', 'total_cases_pm',
'total_deaths_pm']
covidtotals[totvars].quantile(np.arange(0.0, 1.1, 0.1))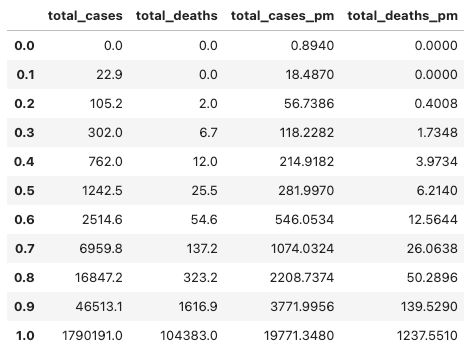
본 포스팅은 파이썬 데이터 클리닝 쿡북을 학습하며 정리한 자료입니다.
728x90
'Python > 기초 문법' 카테고리의 다른 글
| __init__ 메서드란? (0) | 2023.08.03 |
|---|---|
| try-except 구문 (0) | 2023.08.01 |
| [파이썬] 필요한 라이브러리 관리/한 번에 설치하기 (0) | 2023.07.27 |
| Python 스타일 가이드 (0) | 2023.07.21 |
| [스터디] 개발자를 위한 정보검색 팁(공유) (0) | 2023.03.07 |
