상황
이제 팀은 PO가 제시한 인사이트와 분석가의 지표 검증 후, 모든 포지션에 스킬셋(및 역량)을 추가하려고 한다.
기획 분석이 끝나 잠시 시간이 생겨, 데이터 분석가와 데이터 사이언티스트 공고에는 어떤 스킬&역량이 있는지 궁금해졌다고 가정하고 다음 문제를 풀어보자.
📍문제1
SQL
jd 컬럼을 ‘주요업무’, ‘ 자격요건’, ‘ 우대사항’, ‘혜택 및 복지’ 단어로 구분하여 컬럼을 4개로 나눠주세요.
컬럼명은 순서대로 responsibilities, requirements, preference, benefits로 해주세요.
- split()을 활용 : split(자를 컬럼명, 기준 문자열)
- safe_offset() : 오류가 나면 null 처리
- safe_offset(숫자) : 나눈 문자열을 인덱싱하는 기준 숫자 (예 : 0이면 나눠진 값 중 첫번째 문자열)
select position_id,
jd,
split(jd, '주요업무')[safe_offset(1)] as responsibilities
from wanted_sample_data.wanted_position
limit 10
예를 들어, jd 내용에서 '주요업무'를 기준으로 내용을 나눈 후, 두 번째 값(인덱싱 기준 1번)을 확인하면
주요업무 이후 자격요건부터 끝까지 다 나오는 걸 볼 수 있다.

해당 문제를 해결하기 위해 split을 겹쳐 사용하고 명확히 인덱싱한다.
다음과 같이 쿼리 결과를 확인하며 split 결과값의 앞/뒤를 확인하며 쿼리를 작성한다
select position_id,
jd,
split(jd, '주요업무')[safe_offset(1)] as jd_1,
split(split(jd, '주요업무')[safe_offset(1)], '자격요건')[safe_offset(0)] as jd_2
from wanted_sample_data.wanted_position
limit 10
최종 쿼리
select position_id,
jd,
split(jd, '주요업무')[safe_offset(1)] as jd_1,
split(split(jd, '주요업무')[safe_offset(1)], '자격요건')[safe_offset(0)] as responsibilities,
split(split(split(jd, '주요업무')[safe_offset(1)], '자격요건')[safe_offset(1)], '우대사항')[safe_offset(0)] as requirements,
split(split(split(split(jd, '주요업무')[safe_offset(1)], '자격요건')[safe_offset(1)], '우대사항')[safe_offset(1)], '혜택 및 복지')[safe_offset(0)] as preference,
split(split(split(split(jd, '주요업무')[safe_offset(1)], '자격요건')[safe_offset(1)], '우대사항')[safe_offset(1)], '혜택 및 복지')[safe_offset(1)] as benefits,
from wanted_sample_data.wanted_position
limit 10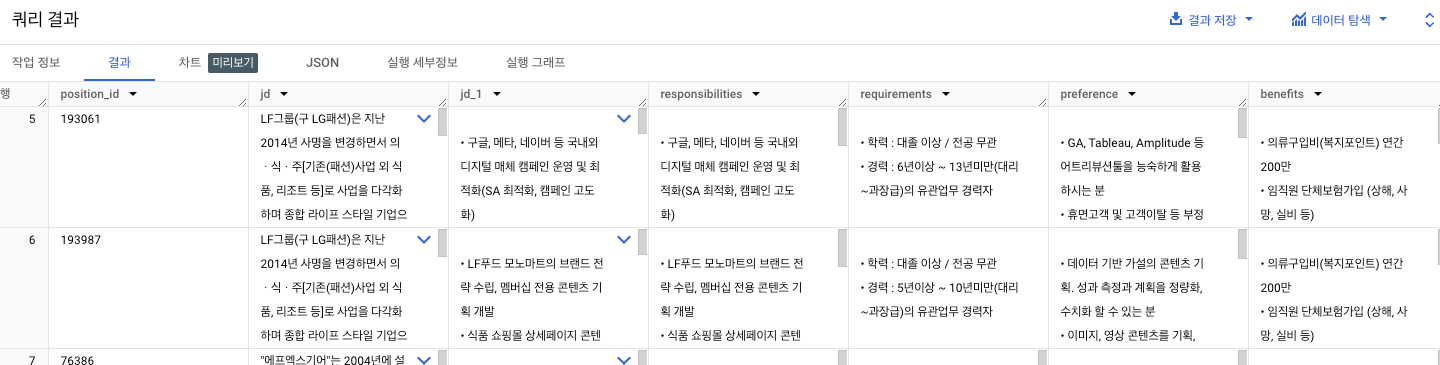
📍문제2
python
krwordrank 패키지를 이용하여 requirements에서 주요 명사들을 추출하세요. (!pip install krwordrank 실행)
+ 추출 결과를 워드클라우드 시각화로 표현하기
1. 빅쿼리에서 코랩으로 데이터 넘기기

2. 간단한 데이터 전처리
import pandas as pd
import numpy as np
# 데이터 복사 및 확인
df = results.copy()
print(df.shape)
print(df.columns)
# 문자열 > 정수로 타입 변환
df['annual_from'] = df['annual_from'].astype(int)
df['annual_to'] = df['annual_to'].astype(int)
# 불필요한 컬럼 제거
df.drop(columns=['preference', 'benefits', 'jd'], axis = 1, inplace = True)
# 공백 처리(워드클라우드 전처리)
df['responsibilities'] = df['responsibilities'].replace(np.nan, '공백제거')
df['requirements'] = df['requirements'].replace(np.nan, '공백제거')

3. 텍스트 주요 키워드 뽑기 (krwordrank 활용)
- krwordrank Import
- 워드클라우드 만들 컬럼 내용을 list로 확보
!pip install krwordrank
from krwordrank.word import KRWordRank
# 워드클라우드 만들 컬럼값을 리스트로
get_list = df['responsibilities'].values.tolist()
print(get_list[0])
- 워드클라우드 만들기 위한 기본 매개변수 세팅
## 조건
min_count = 5 # 단어출현빈도
max_length = 10 # 단어길이 최대값
verbose = True
wordrank_extractor = KRWordRank(min_count = min_count, max_length = max_length, verbose = verbose)
beta = 0.85
max_iter = 10
# keyword : 텍스트에서 추출한 주요 키워드
# rank : 텍스트 점수
# graph : 추출한 텍스트의 관계 그래프
keyword, rank, graph = wordrank_extractor.extract(get_list, beta, max_iter)
for word, r in sorted(keyword.items(), key = lambda x:x[1], reverse = True)[:30]:
print('%s:\t%.3f' % (word, r))
- stopwords 세팅 후 재실행
stopwords = ['and', 'of','데이터', '분석', '위한', 'to', '개발', 'the', '서비스', '기반', '모델', 'for', 'in', '대한', '다양한']
passwords = {
word:score for word, score in sorted(
keyword.items(), key = lambda x:-x[1])[:300] if not (word in stopwords)
}
for word, r in sorted(passwords.items(), key = lambda x:x[1], reverse = True)[:30]:
print('%s:\t%.3f' % (word, r))
4. 워드클라우드 시각화
- 한글 폰트 세팅
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm # 폰트매니저
%config InlineBackend.figure_format = 'retina' # 그래프 이미지의 해상도를 설정합니다.
!apt -qq -y install fonts-nanum # 구글 Colab에서 Nanum 폰트를 설치합니다.
path = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf' # NanumBarunGothic 폰트의 경로를 지정합니다.
fe = fm.FontEntry(
fname=path, # ttf 파일이 저장되어 있는 경로
name='NanumGothic') # 이 폰트의 원하는 이름 설정
fm.fontManager.ttflist.insert(0, fe) # Matplotlib에 폰트 추가
plt.rcParams.update({'font.size': 18, 'font.family': 'NanumGothic'})
- 워드클라우드
from wordcloud import WordCloud
wc = WordCloud(
font_path = path,
width = 1000,
height = 1000,
scale = 3.0, # 해상도
max_font_size=250
)
gen = wc.generate_from_frequencies(passwords)
plt.figure()
plt.imshow(gen)
728x90
'SQL > SQL test' 카테고리의 다른 글
| [HackerRank] Weather Observation Station 20(중앙값) (0) | 2024.01.15 |
|---|---|
| [BigQuery] 현업 문제 해결 쿼리 작성(4) : 성과 확인(A/B test) (1) | 2024.01.14 |
| [BigQuery] 현업 문제 해결 쿼리 작성(2) : 인사이트 적용 전, 지표 분석 (2) | 2024.01.08 |
| [BigQuery] 현업 문제 해결 쿼리 작성(1) : Funnel 분석 (1) | 2024.01.08 |
| [HackerRank] Top Earners 풀이 (mySQL) (1) | 2023.12.23 |



