BorutaPy의 주요 특징
- 랜덤 포레스트 기반
- 부트 스트랩 표본 사용 : 원래 데이터셋에서 무작위로 샘플링하여 모델을 여러번 학습하고 평균 중요도를 계산
- 변수 중요도 평가 : 특정 특성의 중요도와 랜덤하게 생성된 그룹의 중요도를 평가
- 변수 선택 : 모델에 가장 적합한 특성 세트를 찾을 수 있음
사용 과정
1. 데이터 준비, 특성과 타겟 변수를 정의 : 실제 특성과 쉐도우 특성 생성
📍 쉐도우 특성(shadow feature)이란?
- 원본 데이터셋의 특성과 비슷한 특성을 생성하는 것
👉 데이터의 무작위성을 유지하기 위해 원본 특성들과 동일한 분포를 가지도록 생성됨
👉 원본 특성과 동일한 수의 특성이지만, 실제 데이터와는 무관하게 무작위로 생성됨
- 만약 원본 특성이 예측에 중요하다면, boruta 알고리즘은 쉐도우 특성보다 그 중요도가 높아야 함!
2. BorutaPy 객체를 초기화, 모델 훈련시키기
3. 특성의 중요도를 확인 후, 필요한 경우 특성을 선택하거나 제거
4. 선택된 특성을 사용하여 모델을 다시 훈련시키고 평가
실습
라이브러리 import
import pandas as pd
import seaborn as sns
from sklearn.ensemble import RandomForestClassifier
from boruta import BorutaPy
import shap
from feature_engine.selection import DropCorrelatedFeatures
샘플 데이터(titanic) 전처리
# 타이타닉데이터로 보루타 알고리즘으로 피처를 선정
df = sns.load_dataset('titanic')
#데이터 전처리
df = df.dropna(subset=['age','embarked','deck'])
df['sex'] =df['sex'].map({'male':0,'female':1})
df['embarked'] =df['embarked'].astype('category').cat.codes
df['deck'] = df['deck'].astype('category').cat.codes
#필요한 피처만 추출
X = df[['pclass','sex','age','sibsp','parch','fare','embarked','deck']]
y = df['survived']
랜덤포레스트 모델로 Borutapy 활용하기
# 랜덤포레스트 초기화 가지고 오기!
rf = RandomForestClassifier(class_weight= 'balanced', max_depth=5)
# Borutapy 불러오기
boruta_selector=BorutaPy(rf, n_estimators='auto',random_state=111)
# selector 학습
boruta_selector.fit(X.values, y.values)
선택된 특성 출력
# 선택된 특성을 출력
print('Selected Features:', X.columns[boruta_selector.support_].tolist())

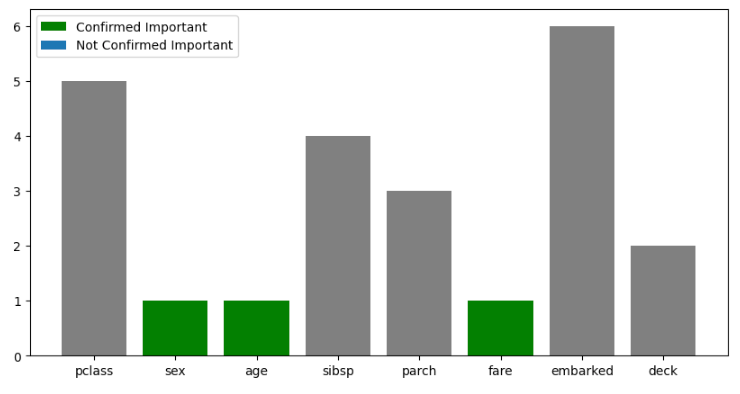
BorutaPy 시각화
# BorutaPy 시각화
import matplotlib.pyplot as plt
green_area = X.columns[boruta_selector.support_].tolist() #중요 특성
blue_area = X.columns[boruta_selector.support_weak_].tolist() #중요도 불확실 특성
# 중요도 기반 링캥
feat_importances = boruta_selector.ranking_
# 시각화
plt.figure(figsize = (10,5))
plt.bar(X.columns, feat_importances, color = 'grey') #모든 특징 중요도
plt.bar(green_area, [1]*len(green_area), color = 'green', label='Confirmed Important')
plt.bar(blue_area, [2]*len(blue_area), color = 'blue', label = 'Not Confirmed Important')
plt.legend()
plt.show()
SHAP(SHapley Additive exPlanations)
👉 머신러닝 모델의 예측을 해석하기 위한 도구로, 각 특성이 예측에 어떻게 기여하는지 설명하는데 사용됨
- 전체적인 효과와 특성의 영향을 분해 : 특성 간의 상호 작용과 전체적인 모델의 예측을 이해할 수 있음
- Shapley값 제공 : 각 특성이 예측에 미치는 영향을 Shapley 값으로 표현함(게임 이론에서 파생된 개념)
- 모델 종류에 대한 일반화 : 선형 모델부터 딥러닝 모델까지 다양한 모델에서 사용 가능
- 모델의 예측을 설명 가능하게 만들면서도 모델 성능을 유지하려고 하여 설명 가능성과 예측 성능 사이의 균형을 유지
shap 요약 플롯
import shap
# 위에서 선택된 sex, age, fare 의 shap값을 확인(feature selection 방법에 대한 이해)
from sklearn.model_selection import train_test_split
X = df[['sex', 'age', 'fare']]
y = df['survived']
# 데이터 분할
X_train, X_test, y_train, y_test =train_test_split(X,y, test_size=0.3, random_state=111)
# 모델 간단히 학습
model = RandomForestClassifier(random_state =111)
model.fit(X_train, y_train)
# SHAP 값 구하기
# SHAP Explainer 초기화 및 SHAP 값 계산
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test) # shap값을 간단히 계산
# shap 요약 플롯
shap.summary_plot(shap_values[0], X_test, plot_type='bar', feature_names = X_test.columns.tolist())
SHAP 특성 영향도 시각화
## Shap 시각화 중 특성들의 영향도를 볼 수 있는 그래프
feature_names = X.columns.tolist()
shap.summary_plot(shap_values[1],X_test, feature_names= feature_names)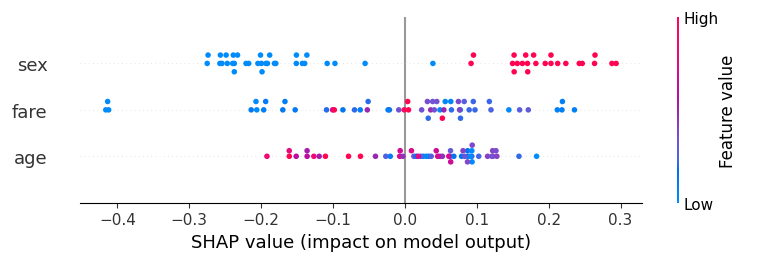
🧩 그래프 설명
- x축 : SHAP 값으로, 모델 예측에 대한 각 특징의 영향도(값이 클수록 예측에 더 큰 영향)
- y축 : 모델의 입력 특징들(sex, age, fare 등)
- 점 : 하나의 데이터 포인트로, 해당 데이터 포인트의 예측에 각 특성이 얼마나 기여했는지 보여줌
- 점의 색상 : 해당 특징 값의 크기(파란색이 낮은 값, 빨간색이 높은 값)
- 점이 오른쪽에 위치할수록 해당 특성이 모델의 예측을 증가시키는 방향으로 기여
- 점의 분포 : 특정 특징에서 점들이 0의 왼쪽에 많다면, 그 특징이 모델 예측을 주로 낮추는 방향으로 작용하고, 오른쪽에 많다면 예측을 높이는 방향으로 작용
- 0 기준선 : SHAP 값이 0인 지점으로, 0보다 크면 모델 예측에 양의 영향을, 0보다 작으면 모델 예측에 음의 영향을 미침
🧩 해석 예시
👉 sex : 주로 파란색(남성)이 모델 예측에 음의 영향을 미치고, 빨간색(여성)이 양의 영향을 미침
👉 fare : 요금이 높은(빨간색) 경우 모델에 양의 영향을 미치는 반면, 요금이 낮은 경우 음의 영향을 미침
----> 높은 요금을 지불한 승객일수록 모델이 예측을 높게 함)
👉 age : 나이가 어린(빨간색) 경우 모델 예측에 양의 영향, 나이가 많은(파란색)의 경우 모델 예측에 음의 영향
다른 모델을 사용해서 SHAP으로 피처를 확인
# 결정트리모델 & 랜덤포레스트 모델
# 피처를 좀 더 추가하고 다시 모델을 2개로 비교해서 시각화
from sklearn.tree import DecisionTreeClassifier
X=df[['pclass','sex','age','fare','embarked']]
y=df['survived']
# 데이터 분할
X_train, X_test, y_train, y_test =train_test_split(X,y, test_size=0.3, random_state=111)
# dt 모델
dt_model = DecisionTreeClassifier(max_depth=3)
dt_model.fit(X_train, y_train)
# rf 모델
rf_model = RandomForestClassifier(max_depth=3, random_state=111)
rf_model.fit(X_train, y_train)
# SHAP 다양한 모델을 사용
# Kernel Explainer
kernel_explainer = shap.KernelExplainer(dt_model.predict_proba, X_train, link='logit')
kernel_values = kernel_explainer.shap_values(X_test, nsamples=100)
# Tree Explainer
tree_explainer = shap.TreeExplainer(rf_model)
tree_shap_values = tree_explainer.shap_values(X_test)
# shap 시각화 Tree
shap.summary_plot(tree_shap_values[1], X_test, plot_type='bar', feature_names=['pclass','sex','age','fare','embarked'])
shap.summary_plot(tree_shap_values[1], X_test, feature_names = ['pclass','sex','age','fare','embarked'])
# shap 시각화 kernel
shap.summary_plot(kernel_values[1], X_test, plot_type='bar', feature_names=['pclass','sex','age','fare','embarked'])
shap.summary_plot(kernel_values[1], X_test, feature_names = ['pclass','sex','age','fare','embarked'])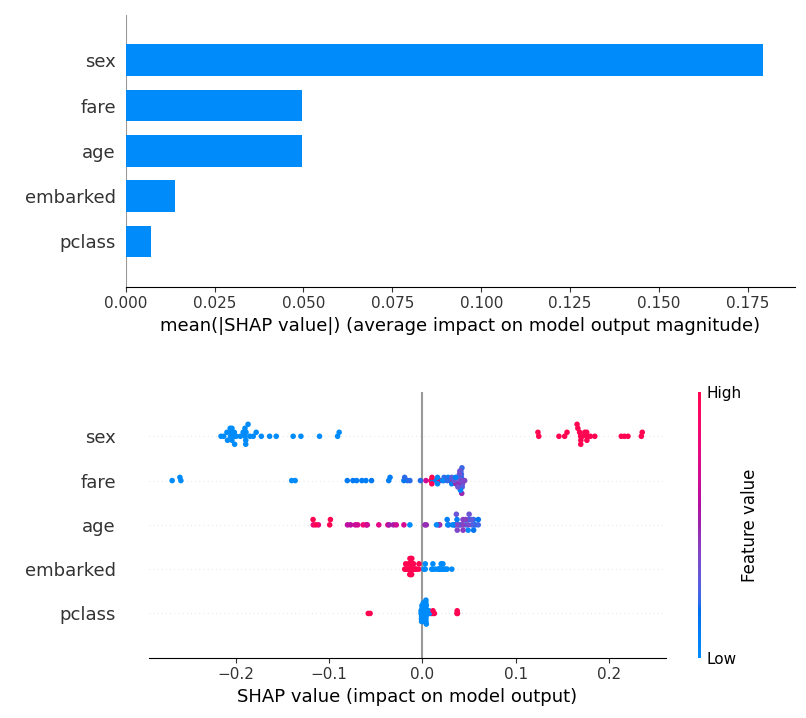
728x90