
스케일링이란?
머신러닝 과정에서는 데이터의 특성(feature)을 추출하여 모델을 학습시킨다.
그러나 데이터 값이나 분산이 너무 크거나 작으면 모델의 학습에 부정적인 영향을 미칠 수 있다.
이를 방지하기 위해 '스케일링' 과정을 통해 데이터 값을 조정하고 분산을 줄이게 된다.
min-max 정규화
min-max 정규화 는 수치형 데이터 값을 0과 1 사이의 값으로 변환해주는 스케일링 방법 중 하나이다
정규화를 위한 수식은 다음과 같다
X' = (X - MIN) / (MAX - MIN)
- X : 원본 데이터 값
- X' : 정규화가 완료된 데이터 값
- MIN : 최솟값
- MAX : 최댓값
sklearn 라이브러리(Library)의 MinMaxScaler 사용법
👉 sklearn 라이브러리(Library)의 MinMaxScaler를 사용하여 train 데이터를 min-max 정규화 해보자 (0과 1사이 값으로 정리)
예시 코드
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(train[train.columns[2:-1]])
train[train.columns[2:-1]] = scaler.transform(train[train.columns[2:-1]])
train- sklearn.preprocessing 모듈에서 MinMaxScaler를 import
- MinMaxScaler 객체를 생성 ▶︎ 생성된 객체를 scaler 변수에 할당
- MinMaxScaler 객체에 train 데이터의 열(column)인 train.columns[2:-1]을 대상으로 fit() 함수를 호출 ▶︎ 최솟값과 최댓값을 기반으로 설정
(train.columns[2:-1]은 index, quality, type을 제외한 2번째 열부터 마지막 열의 이전 열) - 설정된 기반 정보를 바탕으로 train 데이터의 열을 transform() 함수를 통해 정규화
정규화된 값을 train 데이터의 해당 열에 할당
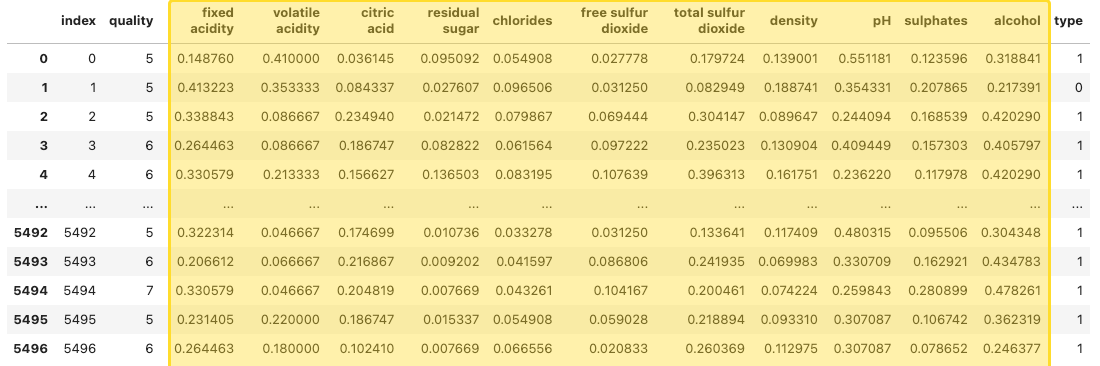
이를 통해 train 데이터의 특성 열이 min-max 정규화된 값으로 업데이트 끝! - 정규화가 적용된 train 데이터프레임을 출력하여 변환된 결과를 확인
결과 예시
728x90
'Machine Learning > scikit-learn' 카테고리의 다른 글
| [교차 검증] Stratified K 폴드 (0) | 2023.08.17 |
|---|---|
| [교차 검증] K-폴드 교차 검증 (0) | 2023.08.17 |
| [하이퍼 파라미터] hyper parameter란? (0) | 2023.08.17 |
| [회귀] LinearRegression (선형 회귀 모델) & 회귀 평가 지표 (0) | 2023.08.15 |
| [앙상블] RandomForestRegressor(랜덤포레스트) (4) | 2023.08.14 |



