히스토그램 차트를 위한 데이터 전처리
- 상품 가격대별로 히스토그램을 그려하기 때문에, 가격의 상한/하한 값을 구하고 그 차이를 계산한다.
WITH stats AS (
SELECT max(price) AS max_price
, min(price) AS min_price
, max(price) - min(price) AS price_range
, 10 AS bucket_num
FROM purchase_detail_log
)
SELECT *
FROM stats
;

2. 상한값에 + 1 을 하여 최댓값도 구간에 포함되도록 한다.
3. 각 가격에서 min_price를 뺀 값을 Diff로 구한다.
4. 계층 범위는 가격 구간을 구간 개수로 나누어 구한다.
5. (diff / 계층 범위) 결과를 내림하면 값의 상대적인 위치를 구할 수 있다.
WITH stats AS (
SELECT max(price) + 1 AS max_price
, min(price) AS min_price
, max(price) + 1 - min(price) AS price_range
, 10 AS bucket_num
FROM purchase_detail_log
),
purchase_log_with_bucket AS (
SELECT price
, min_price
, price - min_price AS diff --대상금액에서 최소 금액을 뺀 것
, 1.0 * price_range / bucket_num AS bucket_range --계층 범위
, FLOOR(1.0 * (price-min_price) / (1.0 * price_range / bucket_num) + 1) AS bucket
FROM purchase_detail_log, stats
)
SELECT *
FROM purchase_log_with_bucket
ORDER BY price
;
👉 참고로, PostgreSQL의 경우 width_bucket 함수를 쓸 수 있다.
width_bucket(price, min_price, max_price, bucket_num) as bucket
히스토그램 ; 구간별 빈도수 구하기
- 위의 쿼리 일부를 그대로 사용한다. bucket 별로 lower_limit과 upper_limit을 구하고 price의 개수를 count 하면 빈도를 구할 수 있다.
- bucket 기준으로 그룹화하면 끝!
WITH stats AS (
SELECT max(price) + 1 AS max_price
, min(price) AS min_price
, max(price) + 1 - min(price) AS price_range
, 10 AS bucket_num
FROM purchase_detail_log
),
purchase_log_with_bucket AS (
SELECT price
, min_price
, price - min_price AS diff --대상금액에서 최소 금액을 뺀 것
, 1.0 * price_range / bucket_num AS bucket_range --계층 범위
, FLOOR(1.0 * (price-min_price) / (1.0 * price_range / bucket_num) + 1) AS bucket
FROM purchase_detail_log, stats
)
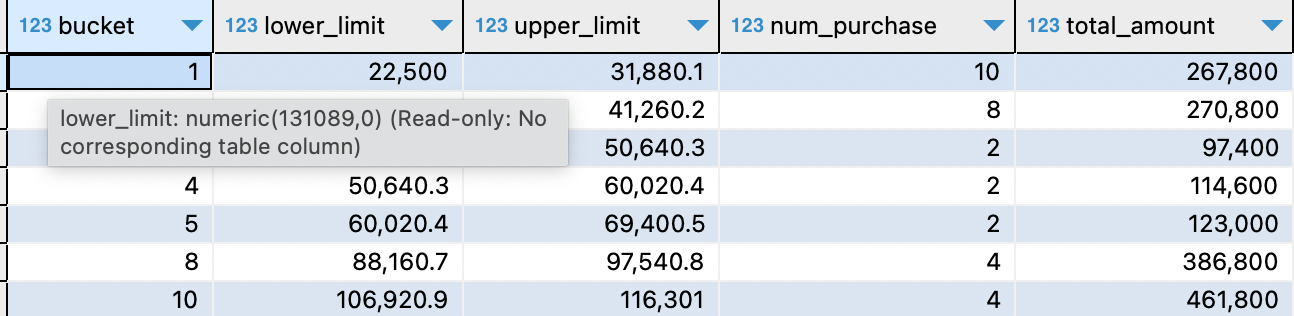
SELECT bucket
, min_price + bucket_range * (bucket - 1) AS lower_limit
, min_price + bucket_range * bucket AS upper_limit
, count(price) AS num_purchase
, sum(price) AS total_amount
FROM purchase_log_with_bucket
GROUP BY bucket, min_price, bucket_range
ORDER BY bucket
;
ORDER BY price
;
히스토그램 ; 구간별 빈도수 구하기
- 위처럼 쿼리를 짜면 구간을 나누는 기준에 소수점이 생기게 된다.
- 임의로 소수점을 제외하고 구간을 나눠야 하는 경우가 필요하기 때문에 다음과 같이 쿼리를 작성한다.
- 0 ~ 50,000원의 범위를 5000단위로 10개 구간으로 나누어 본다.
WITH stats AS (
SELECT 50000 AS max_price
, 0 AS min_price
, 50000 AS price_range
, 10 AS bucket_num
FROM purchase_detail_log
),
purchase_log_with_bucket AS (
SELECT price
, min_price
, price - min_price AS diff
, 1.0 * (price_range - bucket_num) AS bucket_range
, floor(1.0 * (price - min_price) / (1.0 * (price_range - bucket_num))) AS bucket
FROM stats, purchase_detail_log
)
SELECT bucket
, min_price + bucket_range * (bucket - 1) AS lower_limit
, min_price + bucket_range * bucket AS upper_limit
, count(price) AS num_purchase
, sum(price) AS total_amount
FROM purchase_log_with_bucket
GROUP BY bucket, min_price, bucket_range
ORDER BY bucket
;728x90
'SQL > 실무 SQL' 카테고리의 다른 글
| [PostgreSQL] 2. 연령별 구분 집계 (1) | 2024.01.29 |
|---|---|
| [PostgreSQL] 1. 사용자의 액션 수 집계 (0) | 2024.01.29 |
| [PostgreSQL] 팬 차트로 매출 증가율 확인(FIRST VALUE 함수) (0) | 2024.01.27 |
| [PostgreSQL] 카테고리별 매출 총계와 소계 / ABC 분석 (0) | 2024.01.26 |
| [PostgreSQL] 매출을 파악하기 위한 데이터 추출2 (종합 쿼리) (0) | 2024.01.26 |



