직전 포스팅과 이어지는 예제입니다.👀
[활동2 ]Worldometer에서 나라별 인구수 크롤링
앞선 예제에서 웹사이트에 소개된 나라의 이름들을 가져왔다.
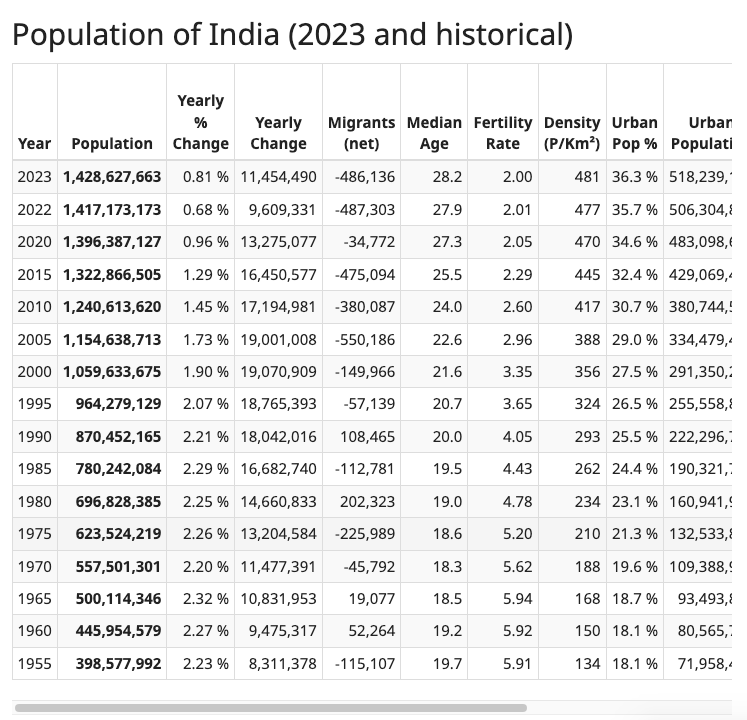
각 나라의 이름을 클릭하면 다음과 같이, 연도별 인구수가 나온다.
이렇게 나라별 링크를 타고 들어가, 연도별 인구수까지 크롤링해 보는 것이 두 번째 활동이다.
🧑🏻💻 def parse 부터 코드 작성 시작
- 나라 이름(contries) 정보는 countries = response.xpath('//tbody/tr/td/a') 에 Text() 로 저장되어 있다.
- 나라별로, 상대경로를 통해 링크에 진입해서 연도별 인수구를 알아내야 한다.
- for country in countries: 반복문을 사용하여 country_name과 link를 각각 추출해 저장한다.
- yield response.follow: 추출한 링크를 사용하여 나라별 페이지를 요청하고, parse_country 콜백 메서드를 호출
- meta 인자를 사용하여 현재 나라의 이름을 parse_country 메서드로 전달
🧐 현재 크롤링한 페이지에서 다른 링크 내용 크롤링하기
- url : 크롤러가 이동하고자 하는 새로운 페이지의 url 지정
- callback : 새로운 페이지의 응답을 처리하기 위해 호출될 메서드 지정 >> 새로운 페이지의 데이터를 추출, 처리하는 역할
👉 즉, 여기서는 parse_country를 콜백으로 처리할 것임
- meta : 새로운 페이지에 대한 추가 정보를 전달하는 데 사용되는 파라미터 >> 현재 페이지에서 추출한 정보를 다른 페이지의 콜백 메서드로 전달할 수 있음
👉 여기서는 나라의 이름을 parse_country 메서드로 전달
import scrapy
class WorldometerSpider(scrapy.Spider):
name = "worldometer"
allowed_domains = ["www.worldometers.info"]
start_urls = ["https://www.worldometers.info/world-population/population-by-country/"]
def parse(self, response):
countries = response.xpath('//tbody/tr/td/a')
for country in countries:
country_name = country.xpath('.//text()').get()
link = country.xpath('.//@href').get()
yield response.follow(url=link, callback=self.parse_country, meta = {'country': country_name})
- parse_country() 메서드 : 각 나라별 페이지의 응답을 처리
- country : meta 인자를 통해 전달된 현재 나라의 이름을 가져옴
- rows : 인구데이터가 있는 테이블의 행들을 xpath를 사용하여 선택
- for row in rows : 반복문을 시행하여 연도와 인구 데이터를 추출
- yield : 추출한 나라 이름, 연도, 인구데이터를 딕셔너리 형태로 반환하여, 크롤링한 데이터 출력
def parse_country(self, response):
country = response.request.meta['country']
rows = response.xpath('(//table[contains(@class, "table")])[1]/tbody/tr')
for row in rows:
year = row.xpath('.//td[1]/text()').get()
population = row.xpath('.//td[2]/strong/text()').get()
yield {
'country' : country,
'year' : year,
'population' : population
}728x90
'Programming Basics' 카테고리의 다른 글
| [크롤링] 게시글 제목 크롤링해서 DataFrame으로 만들기 (0) | 2023.10.04 |
|---|---|
| M1 환경설정 XGBoost & LightGBM with Streamlit in Python (0) | 2023.09.07 |
| [Scrapy 크롤링] Worldometer에서 나라이름 크롤링 (0) | 2023.08.08 |
| XPath란 (0) | 2023.08.08 |
| [크롤링] 셀레늄(selenium) 활용 ; nate 검색어 1위부터 10까지 가져오기(동적화면에서의 크롤링) (0) | 2023.08.08 |


