
부스팅이란?
- 순차적으로 모델의 정확도를 높이는 방법
- 전체 학습데이터에서 일부를 선택하여 하위 데이터 세트와 이를 학습할 첫 번째 모델을 만듦
- 첫 번째 모델이 잘 학습하지 못한 부분을 반영해서 두 번째 데이터 세트와 모델을 만들고, 이 과정을 반복하여 점진적으로 모델 정확도를 높임
XGBoost(Extreme Gradient Boosting)란?
- 이러한 부스팅 기법을 이용하여 구현한 알고리즘은 Gradient Boost 가 대표적
- 이 알고리즘을 병렬 학습이 지원되도록 구현한 것이 XGBoost (학습시간 단축을 위함)
- GBM에 기반하고 있지만, GBM의 단점인 느린 수행 시간 및 과적합 규제 부재 등의 문제를 해결함
- 병렬 CPU 환경에서 병렬 학습이 가능해 기존 GBM보다 학습을 빠르게 완료
XGBoost의 주요 장점
- 뛰어난 예측 성능
- GBM 대비 빠른 수행 시간
- 과적합 규제 : 자체에 과적합 규제 기능으로, 과적합에 좀 더 강한 내구성이 있음
- 나무 가지치기(Tree Pruning) : 더 이상 긍정 이득이 없는 분할을 가지치기 해서 분할 수를 더 줄이는 추가적인 장점이 있음
- 자체 내장된 교차 검증 : 반복 수행 시마다 내부적으로 학습/평가 데이터 세트를 나누어 교차 검증을 수행해 최적화된 반복 수행 횟수를 가짐(평가 데이터 세트의 평가 값이 최적화되면 반복을 중간에 멈출 수 있는 조기 중단 기능 있음)
- 결손값 자체 처리
XGBoost 사용법
- XGBoost 프레임워크 기반의 파이썬 래퍼 모듈
- 사이킷런과 연동되는 사이킷런 래퍼 모듈이 있음
사이킷런 래퍼 XGBoost의 모델 학습과 예측
fit( ) 메서드의 매개변수
from xgboost import XGBClassifier
# XGBClassifier 객체 생성
xgb_ml = XGBClassifier(n_estimators = 400, learning_rate = 0.05, max_depths = 3, eval_metrics = 'logloss')
evals = [(X_tr, y_tr), (X_val, y_val)]
# 모델 학습
xgb_ml.fit(X_train,y_train, early_stopping_rounds=50, eval_set=evals, verbose=True)
y_pred = xgb_ml.predict(X_test)- eval_set : 모델 학습 중 성능을 평가할 데이터 세트를 지정
- 검증 데이터를 사용하며, 데이터를 튜플로 묶어서 eval_set 매개변수에 리스트 형태로 전달
- 부스팅이 종료될 때마다 해당 데이터셋을 사용하여 모델 성능을 확인하며 검증 점수를 반환
- verbose : 학습 결과 출력 조건을 설정
- verbose를 10으로 설정할 경우, 부스팅을 수행한 횟수가 10의 배수 일때, eval_metric 매개변수에 입력한 평가 지표에 대한 검증 점수를 반환
XGBoost의 모델 검증 시각화
RMSE = rmse(y_valid, y_pred)
plt.figure(dpi=150)
plt.title('RMSE : ' + str(RMSE)[:8])
plt.plot(y_valid.reset_index(drop=True), alpha=0.6, label='real')
plt.plot(y_pred, alpha=0.6, label='pred')
plt.legend()
plt.show()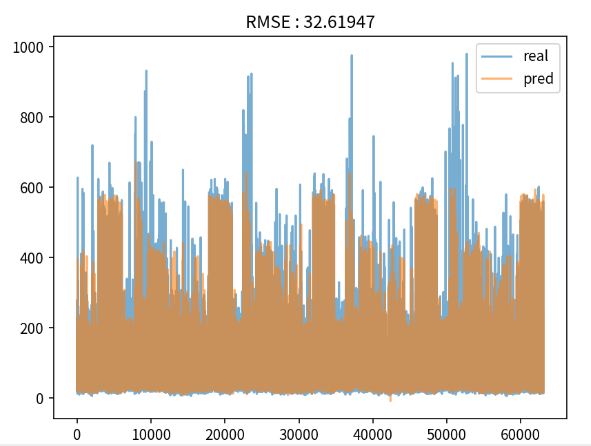
728x90
'Machine Learning > scikit-learn' 카테고리의 다른 글
| [데이터 전처리] Label encoding(레이블 인코딩) (0) | 2023.09.27 |
|---|---|
| [교차 검증] cross_val_score() (0) | 2023.09.26 |
| [앙상블 학습] LightBGM (0) | 2023.08.22 |
| [앙상블] 파이썬 래퍼 XGBoost 개념과 예제 (0) | 2023.08.22 |
| [앙상블] GBM(Gradient Boosting Machine) (0) | 2023.08.22 |



