train_test_split()
▶︎ train_test_split 모듈 사용 : 학습 데이터 셋과 test 데이터 셋을 손쉽게 분리할 수 있음
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid =
train_test_split(X, y, test_size=비율(0~1 사이), random_state=숫자)- X : 학습에 사용되는 독립 변수 데이터 (배열이나 데이터프레임)
- y : 예측하고자 하는 종속 변수 데이터
- test_size : 테스트용 데이터 개수를 지정. (1보다 작은 실수를 기재할 경우, 비율을 나타냄)
- train_size : 학습용 데이터의 개수를 지정. (1보다 작은 실수를 기재할 경우, 비율을 나타냄)
- train_size와 test_size는 둘 중 하나만 기재해도 됨
- random_state : 난수 시드 (동일한 데이터셋을 얻기 위한 파라미터)
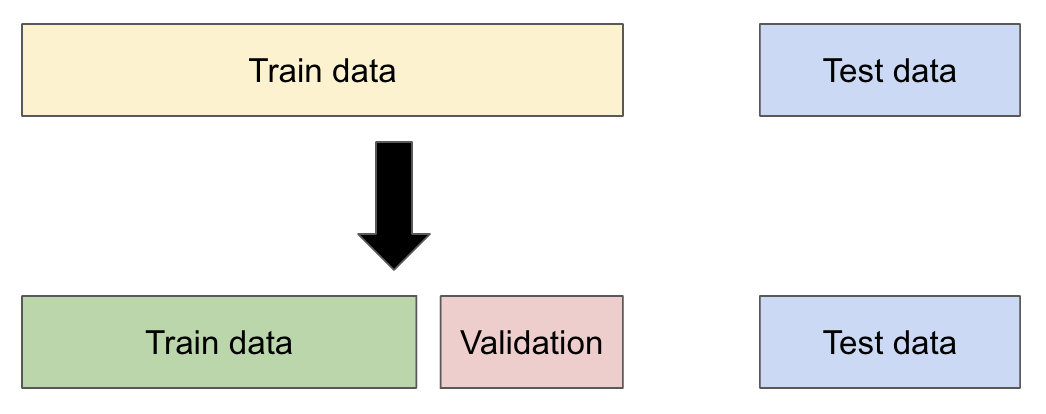
👀 왜 데이터를 분리해야 할까?
머신러닝 모델을 학습시킬 때 학습 데이터만 사용하고 test 데이터로 예측을 수행하면, 예상보다 성능이 낮게 나타날 수 있다.
👉 일반적으로 과적합(Overfitting) 이라고 하는 현상 : 모델이 학습 데이터에 지나치게 맞추어져 다른 데이터에 대한 예측 정확도가 현저히 떨어지게 됨(아래 이미지 참고)
👉 따라서, 학습 데이터와 테스트 데이터를 분리하여 모델의 적합성을 평가해야 함

728x90
'Machine Learning' 카테고리의 다른 글
| 회귀 트리와 선형 회귀 (0) | 2023.08.23 |
|---|---|
| [회귀] 자전거 대여 수요 예측 (0) | 2023.08.23 |
| [Decision Tree] 의사결정나무 모델 (0) | 2023.08.15 |
| [DecisionTreeRegressor] 회귀 트리 모델 (0) | 2023.08.14 |
| [pingouin] 통계분석 결과를 데이터프레임으로 확인할 수 있는 라이브러리 (0) | 2023.08.11 |



