회귀 연습 : 자전거 대여 수요 예측
- 회귀 예제 : 선형 회귀와 트리 기반 회귀
- 케글 데이터 활용
- 구글 코랩에서 실습 진행 후, 정리
데이터 클렌징 및 가공, 시각화
1. 라이브러리 임포트
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
2. 데이터 불러오기
- 전체적인 데이터 크기와 구성을 확인
bike_df = pd.read_csv('/content/drive/MyDrive/data/bike_sharing/train.csv')
print(bike_df.shape)
bike_df.head(3)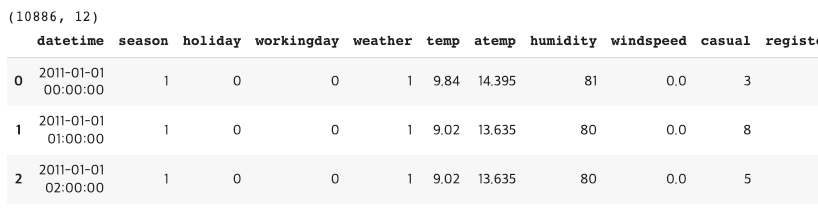
bike_df.info()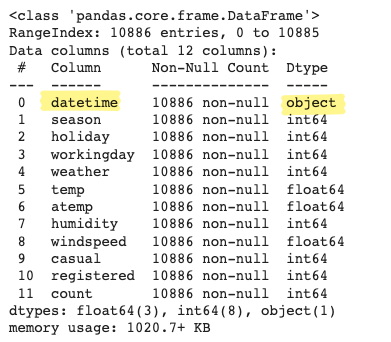
3. object 타입 데이터 다루기
- datetime 컬럼만 문자형으로 되어 있음 ➡ 판다스의 apply(to_datetime) 메서드 이용해서 타입 변경
- datetime 타입으로 변경
- 연, 월, 일 시간 정보 추출
# 문자열을 datetime 타입으로 변경.
bike_df['datetime'] = bike_df.datetime.apply(pd.to_datetime)
# datetime 타입에서 년, 월, 일, 시간 추출
bike_df['year'] = bike_df.datetime.apply(lambda x : x.year)
bike_df['month'] = bike_df.datetime.apply(lambda x : x.month)
bike_df['day'] = bike_df.datetime.apply(lambda x : x.day)
bike_df['hour'] = bike_df.datetime.apply(lambda x: x.hour)
bike_df.head(3)
4. 예측에 중요하지 않은 컬럼 삭제
drop_columns = ['datetime', 'casual', 'registered']
bike_df.drop(drop_columns, axis = 1, inplace = True)
bike_df.head(3)
5. 반복문을 사용하여 데이터 시각화 한번에 보기
- enumerate 를 사용하여, 인덱스 값을 받아, 이를 4로 나눈 몫과 나머지로 그래프의 위치를 지정해주는 방식
# 시각화할 컬럼 지정
cat_features = ['year', 'month','season','weather','day', 'hour', 'holiday','workingday']
# 전체적인 그래프 틀 만들기(8개 그래프)
fig, ax = plt.subplots(figsize = (16, 8), ncols = 4, nrows = 2)
# 컬럼별로 시각화 반복문
for i, feature in enumerate(cat_features):
row = int(i/4) # 몫(0, 1)
col = i%4 # 나머지 0, 1, 2, 3
sns.barplot(x = feature, y = 'count', data = bike_df, ax = ax[row][col])
ax[row][col].set_title(f'ax[{row}][{col}]')
plt.tight_layout()
plt.show()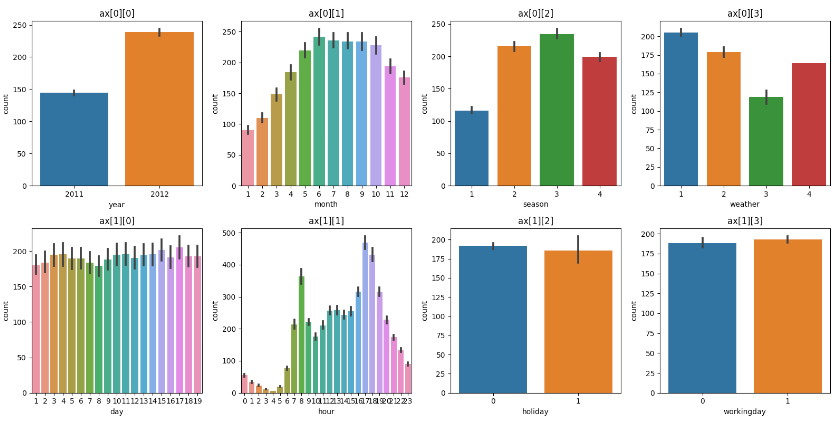
평가 지표 구현하기
RMSLE 함수 만들기
- scikit-learn에서는 RMSLE를 제공하지 않아 직접 작성
- 실제 y값과, 예측값에 넘파이의 log1p()를 사용하여 로그 변환 취해줌
- 로그 변환된 두 값의 차(에러)를 제곱
- 제곱값에 루트 씌우기
- rmse 함수도 함께 작성
- 위에서 작성한 rmsle와 rmse를 모두 반환하는 종합 함수 작성
- mean_absolute_error까지 함께 확인할 수 있도록 코드 추가
from sklearn.metrics import mean_squared_error, mean_absolute_error
# log값 변환 시 NaN 등의 이슈로 log()사용 안함, 대신log1p() 사용
def rmsle(y, pred):
log_y = np.log1p(y)
log_pred = np.log1p(pred)
squared_error = (log_y - log_pred)**2
rmsle = np.sqrt(np.mean(squared_error))
return rmsle
# mean_squared_error() 이용해서 RMSE 계산
def rmse(y, pred):
return np.sqrt(mean_squared_error(y, pred))
# MAE, RMSE, RMSLE 를 모두 계산
def evaluate_regr(y,pred):
rmsle_val = rmsle(y,pred)
rmse_val = rmse(y,pred)
# MAE 는 scikit learn의 mean_absolute_error() 로 계산
mae_val = mean_absolute_error(y,pred)
print('RMSLE: {0:.3f}, RMSE: {1:.3F}, MAE: {2:.3F}'.format(rmsle_val, rmse_val, mae_val))
학습데이터와 테스트 데이터 분리
- X, y 변수 나눠주기
- count가 목표값
- 이외 컬럼이 X 값
- train_test_split으로 학습데이터와 테스트데이터 분할
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LinearRegression, Ridge, Lasso
# 정규화, 표준화 작업 선진행 해줘야 함
y_target = bike_df['count']
X_features = bike_df.drop(['count'], axis = 1, inplace = False)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size = 0.3, random_state = 11)
X_train.shape, X_test.shape, y_train.shape, y_test.shape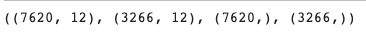
모델 생성, 학습, 예측 & 평가 수행
- 선형 회귀, 릿지, 라쏘 모델 : 3개 모델 정의
- 결과 : 예측 오류로서 비교적 큰 값으로, 실제값과 예측값이 얼마나 차이나는지 확인 필요
from sklearn.linear_model import LinearRegression, Ridge, Lasso
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
pred = lr_reg.predict(X_test)
evaluate_regr(y_test, pred)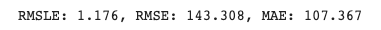
오류값 top5 체크
- 오류값 중 상위 5개만 뽑는 함수
- 실제 y값만 추출해서 result_df 생성
- result_df 에 예측 y 값 컬럼 추가 (prediction_count)
- 두 값의 차이를 나타내는 컬럼 추가 (diff)
- result_df 데이터프레임을 diff 값 기준으로 내림차순하여, 첫 5개만 보여주기
- 결과 해석
- 실제 값을 감안했을 때, 예측 오류가 꽤 큼
- 해결하기 위해, Target 값의 분포가 왜곡되어 있는지 확인(정규 분포형태가 가장 좋음)
def get_top_error_data(y_test, pred, n_tops = 5):
result_df = pd.DataFrame(y_test.values, columns = ['real_count'])
result_df['prediction_count'] = np.round(pred)
result_df['diff'] = np.abs(result_df['real_count'] - result_df['prediction_count'])
print(result_df.sort_values('diff', ascending =False)[:n_tops])
get_top_error_data(y_test, pred, n_tops=5)
Target 값 분포 확인(정규분포인가)
- 결과 확인
- 0 ~ 200 에 분포가 집중되어, 왜곡이 심함 ➡ 정규화 필요(로그 변환 예정)
y_target.hist()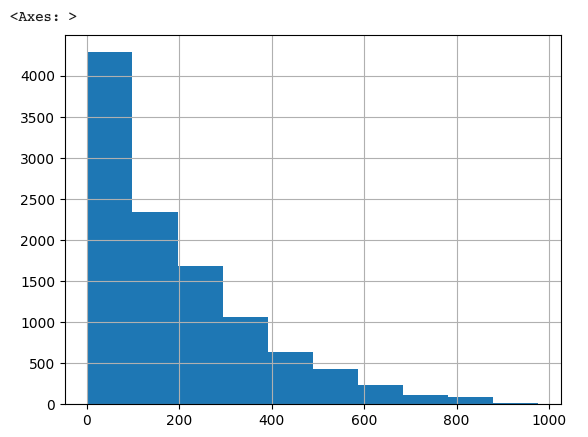
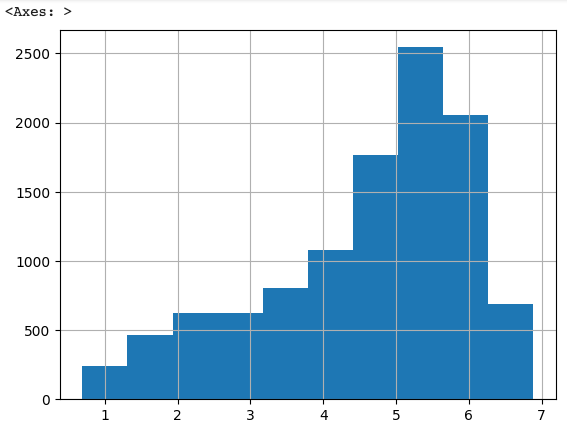
Target 값 로그 변환
- numpy의 log1p()를 이용해서 y_target 값을 로그변환
- 로그변환 후, 분포 다시 확인
- 결과 확인
- 변환 전에 비해 왜곡이 많이 줄었음! ➡ 이제 다시 학습과 예측을 수행해보자!
y_log_transform = np.log1p(y_target)
y_log_transform.hist()
모델 재학습 & 재예측
- 로그 변환된 y_target 값을 y_target_log에 할당
- train_test_split으로 변환된 y_target_log와 기존 x 변수를 분할
- 모델 생성(선형회귀) & 학습 & 테스트
- 테스트 결과 측정을 위해 로그변환된 값을 원래 스케일로 변환
- np.expm1() 사용
- y_test, pred 둘 다 원래 스케일로 변환
- 최종 결과 확인 : RMSLE: 1.027, RMSE: 161.615, MAE: 108.537
- RMSLE 값 : 약간의 개선을 확인!👍
- RMSE 값 : 오히려 늘었다..! ➡ 개별 피쳐들의 회귀 계숫값 확인 필요
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LinearRegression, Ridge, Lasso
y_target_log = np.log1p(y_target)
X_features = bike_df.drop(['count'], axis = 1, inplace = False)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target_log, test_size = 0.3, random_state = 11)
# X_train.shape, X_test.shape, y_train.shape, y_test.shape
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
pred = lr_reg.predict(X_test)
# 테스트 데이터 세트의 타깃값을 원래 스케일로 변환
y_test_exp = np.expm1(y_test)
# 예측값도 스케일 원상복구
pred_exp = np.expm1(pred)
evaluate_regr(y_test_exp, pred_exp)
각 피쳐의 회귀 계수 시각화
- 결과 확인
- year, hour, month 는 숫자값이지만, 카테고리형 피쳐로 개별 값의 크기가 의미있는 것이 아님
- 사이킷런은 카테고리만을 위한 데이터 타입이 없어, 모두 숫자형으로 변환해야 함 ➡ 개별 피쳐들의 크기에 우위가 없는 원핫 인코딩 시행 필요
coef = pd.Series(lr_reg.coef_, index = X_features.columns)
coef_sort = coef.sort_values(ascending = False)
sns.barplot(x = coef_sort.values, y = coef_sort.index)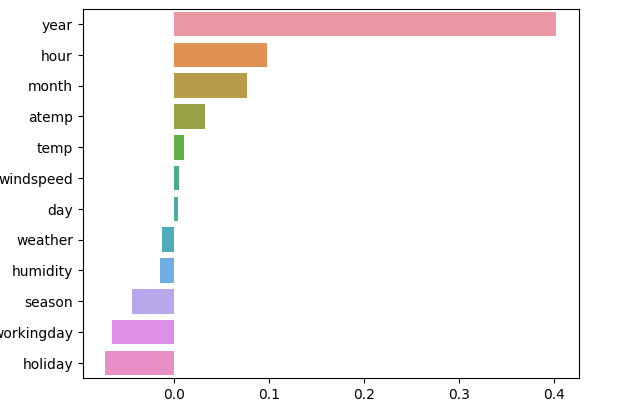
카테고리형 피쳐 원핫 인코딩
- pd.get_dummies 를 이용
- 인코딩할 데이터프레임과 컬럼을 명시
# 'year', month', 'day', hour'등의 피처들을 One Hot Encoding
X_features_ohe = pd.get_dummies(X_features, columns=['year', 'month','day', 'hour', 'holiday',
'workingday','season','weather'])
원핫 인코딩 후, 모델 재구축
👉 로그 변환 + 원핫인코딩 후에 모델 학습 & 평가를 진행하여 예측 성능에 개선이 있는지 확인
- 테스트/훈련데이터 : X값은 원핫인코딩 된 값 + y 값은 로그 변환된 값
- 모델이 학습하고 예측하여 결과 반환까지 하는 함수 작성
- model을 받아 fit()으로 학습시키고
- predict()로 예측한 다음,
- 로그 변환된 y_test 값과 예측 결과인 pred 값을 다시 지수변환 시켜 저장
- 모델 이름 호출(Print)
- 테스트 결과 호출 함수
- 3개의 모델로 평가를 진행할 예정이므로, 각 모델 인스턴스를 생성해주고 Model 리스트에 저장
- 반복문을 사용하여 각 모델들이 학습/예측/평가를 수행하도록 함
# 테스트/훈련 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X_features_ohe, y_target_log, test_size = 0.3, random_state = 0)
# 보관하면 좋은 메서드🔥
def get_model_predict(model, X_train, X_test, y_train, y_test, is_expm1=False): #지수변환
model.fit(X_train, y_train)
pred = model.predict(X_test)
if is_expm1: # 지수변환 요청
y_test = np.expm1(y_test)
pred = np.expm1(pred)
print('###', model.__class__.__name__, '###')
evaluate_regr(y_test, pred)
# model 별로 평가 수행
lr_reg = LinearRegression()
ridge_reg = Ridge(alpha=10)
lasso_reg = Lasso(alpha=0.01)
for model in [lr_reg, ridge_reg, lasso_reg]:
get_model_predict(model, X_train, X_test, y_train, y_test, is_expm1=True)
🚀 예측 성능이 전체적으로 많이 향상 됨을 확인
➡ 중간 점검 차원에서, 회귀계수가 높은 피처를 다시 한 번 확인해보자
- 회귀계수 높은 순으로, 상위 20개 피쳐 확인
- 결과적으로, 이전 회귀계수에 비해 원핫 인코딩 후 피쳐별 영향도가 달라졌음을 확인 가능
coef = pd.Series(lr_reg.coef_, index = X_features_ohe.columns)
coef_sort = coef.sort_values(ascending=False)[:20]
sns.barplot(x=coef_sort.values, y= coef_sort.index)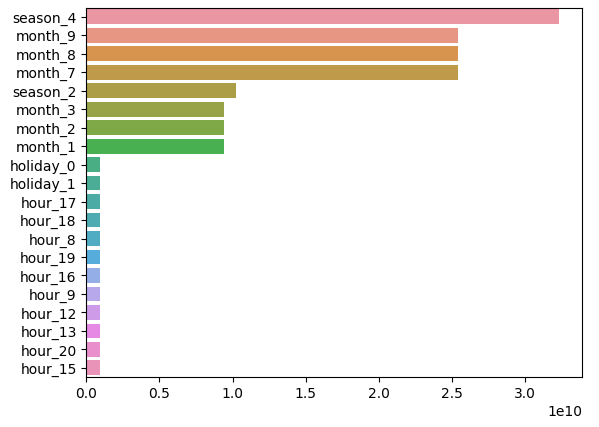
🚀 회귀 트리를 이용한 회귀 예측(최종)
- 앞서 실시한 Target 값의 로그 변환 & 원핫인코딩 처리된 데이터 세트를 이용
- 랜덤포레스트, GBM, XGBoost, LightGBM 으로 순차 성능 평가
- 결과
- 회귀 예측 성능 개선됨
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
# 랜덤 포레스트, GBM, XGBoost, LightGBM model 별로 평가 수행
rf_reg = RandomForestRegressor(n_estimators=500)
gbm_reg = GradientBoostingRegressor(n_estimators=500)
xgb_reg = XGBRegressor(n_estimators=500)
lgbm_reg = LGBMRegressor(n_estimators=500)
for model in [rf_reg, gbm_reg, xgb_reg, lgbm_reg]:
# XGBoost의 경우 DataFrame이 입력 될 경우 버전에 따라 오류 발생 가능. ndarray로 변환.
get_model_predict(model,X_train.values, X_test.values, y_train.values, y_test.values,is_expm1=True)
728x90
'Machine Learning' 카테고리의 다른 글
| One-Hot Encoding(원-핫 인코딩) (0) | 2023.08.31 |
|---|---|
| 회귀 트리와 선형 회귀 (0) | 2023.08.23 |
| 데이터 분리 : train 데이터와 Validation 데이터 (0) | 2023.08.17 |
| [Decision Tree] 의사결정나무 모델 (0) | 2023.08.15 |
| [DecisionTreeRegressor] 회귀 트리 모델 (0) | 2023.08.14 |


