
울산항(TARGET 항구) 추가 데이터 수집 및 전처리
👉 울산항 입항 선박 제원 정보 + 해양 기상 데이터 병합
👉 결측치 채우는 전처리 과정
결측치 확인
- 호출부호, 입항일시 기준 중복 행을 제거한 후, 결측치를 확인
- 대기율, 선박 관련된 컬럼(총톤수, 재화중량톤수 등)과 기상 상태 컬럼(풍속, 풍향 등)이 있음
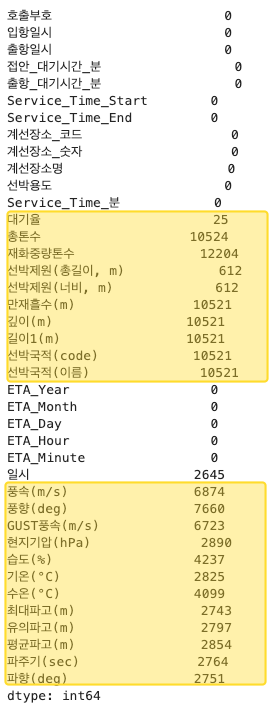
▶︎ 대기율 결측치
- 대기율이 결측치인 레코드는 제거
- 대기율이 중요한 지표인데, Null이 발생한 이유를 찾아야 함
- 대기율을 도출하는데 필요한 '접안대기시간'과 '서비스 시간' 값이 모두 0인 것을 확인하고 삭제 결정
# 대기율이 null 인 데이터만 확인
rows_with_null = df[df['대기율'].isnull()]
# null인 이유를 다른 컬럼과 비교하여 확인
rows_with_null[['접안_대기시간_분','Service_Time_분','대기율']].head()
# 결측치 있는 레코드는 삭제
df = df.dropna(subset = '대기율')
▶︎ 선박 제원 정보(선박 프로필) 결측치
(1) 선박 제원 정보 데이터 형식 변경
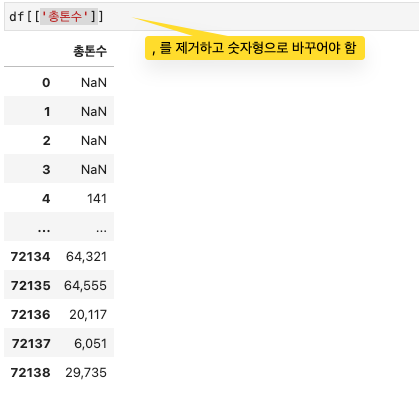
- 쉼표를 제거해야할 컬럼을 지정하고, 해당 데이터에 replace() 를 사용해서 쉼표를 빈 문자열로 바꿈
- {',' : ''} 딕셔너리를 사용하여 쉼표(,)를 빈 문자열로 바꿈
- regex = True 옵션으로 열의 모든 쉼표를 찾아서 제거함(문자열 치환을 정규 표현식으로 처리
# 쉽표 제거하기
columns_to_fix = ['총톤수', '재화중량톤수', '선박제원(총길이, m)', '선박제원(너비, m)', '만재흘수(m)', '깊이(m)', '길이1(m)']
df[columns_to_fix] = df[columns_to_fix].replace({',': ''}, regex=True)
(2) 선박 제원 정보 데이터 타입 변경
- 숫자형으로 변환 : 숫자로 변환할 수 없는 값은 결측치(NaN)으로 대체
df[columns_to_fix] = df[columns_to_fix].apply(pd.to_numeric, errors = 'coerce')
(3) 선박 제원 정보 결측치 대체
- 결측치를 선박용도별 중앙값(또는 평균)으로 채우기 위해 groupby 수행
grouped_by_usage = df.groupby('선박용도')[columns_to_fix]
grouped_by_usage.head()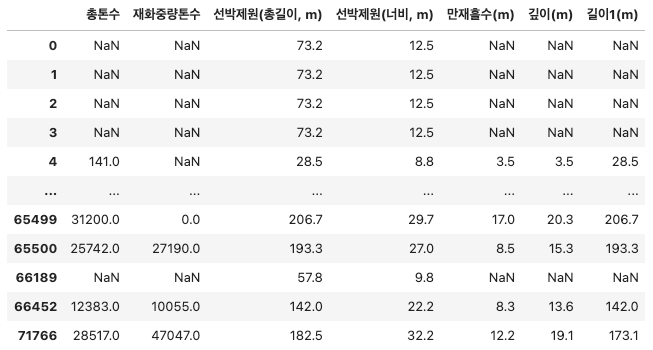
- 선박제원특성에 대한 시각화 >> 전체적으로 왜도가 커서 '중앙값'으로 결측치 대체 예정
fig, axes = plt.subplots(nrows=2, ncols=4, figsize=(16, 8))
for i, column in enumerate(columns_to_fix):
ax = axes[i // 4, i % 4]
ax.hist(df[column].dropna(), bins=30) # 결측치는 제거하고 시각화(히스토그램)
ax.set_title(f'Distribution of {column}')
ax.set_xlabel(column)
ax.set_ylabel('Frequency')
plt.tight_layout()
plt.show()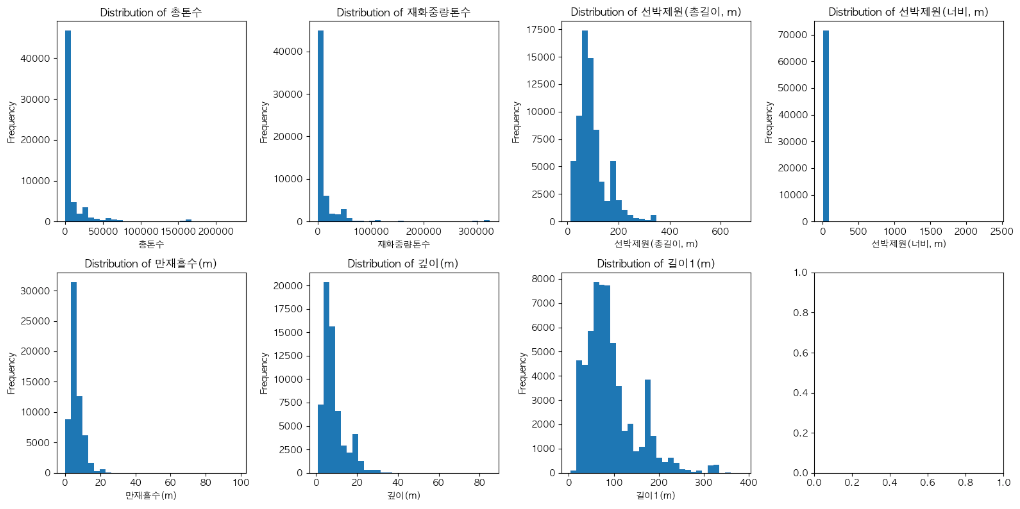
- 선박용도별 선박제원특성 중앙값 도출 및 결측치 대체
👉 데이터프레임(df)에서 '선박용도' 열을 기준으로 그룹화한 후, 각 그룹 내에서 특정(예 :'총톤수') 열의 누락된 값을 해당 그룹 내 해당('총톤수') 열의 중앙값(median)으로 채우는 작업
for col in columns_to_fix:
df[col] = df.groupby('선박용도')[col].transform(lambda x : x.fillna(x.median()))
# 아래는 풀어서 쓴 것
df['총톤수'] = df.groupby('선박용도')['총톤수'].transform(lambda x: x.fillna(x.median()))
df['재화중량톤수'] = df.groupby('선박용도')['재화중량톤수'].transform(lambda x: x.fillna(x.median()))
df['선박제원(총길이, m)'] = df.groupby('선박용도')['선박제원(총길이, m)'].transform(lambda x: x.fillna(x.median()))
df['선박제원(너비, m)'] = df.groupby('선박용도')['선박제원(너비, m)'].transform(lambda x: x.fillna(x.median()))
df['만재흘수(m)'] = df.groupby('선박용도')['만재흘수(m)'].transform(lambda x: x.fillna(x.median()))
df['깊이(m)'] = df.groupby('선박용도')['깊이(m)'].transform(lambda x: x.fillna(x.median()))
df['길이1(m)'] = df.groupby('선박용도')['길이1(m)'].transform(lambda x: x.fillna(x.median()))
- 데이터가 하나 밖에 없는 선박 용도는 제거
df[df['총톤수'].isnull()]['선박용도'] # 하나밖에 없는 선박용도
- 국가코드, 일시 제거
df.drop(columns = ['선박국적(code)','선박국적(이름)'], inplace = True)
df.drop(columns = '일시', inplace = True)
▶︎ 기상 데이터 (시계열 데이터 - 선형 보간)
# 데이터 컬럼 순서 정렬
df = df[['ETA_Year', 'ETA_Month', 'ETA_Day', 'ETA_Hour'] + [col for col in df.columns if col not in ['ETA_Year', 'ETA_Month', 'ETA_Day', 'ETA_Hour']]]
# 보간할 컬럼 선정
columns_to_interpolate = ['풍속(m/s)', '풍향(deg)', 'GUST풍속(m/s)', '현지기압(hPa)', '습도(%)', '기온(°C)',
'수온(°C)', '최대파고(m)', '유의파고(m)', '평균파고(m)', '파주기(sec)', '파향(deg)']
✔️ pandas interpolate로 선형보간 수행 : 중복된 날짜 행이 무시되고 내부 데이터에 대해 시계열 기반의 선형 보간 적용
👉 결측값의 시계열 데이터가 일치하는 행을 제외하고 선형 보간 (method = 'time')
👉 중복된 (날짜)행을 무시하고 내부 데이터만을 기준으로 보간 (limit_area = 'inside')
👉 보간을 양방향으로 적용하며, 결측값 앞뒤 양쪽 방향으로 값을 보간 (limit_direction='both')
# 날짜 및 시간 정보를 합치고 DatetimeIndex 생성 (method = time 사용을 위함)
df['Datetime'] = pd.to_datetime(df['ETA_Year'].astype(str) + '-' + df['ETA_Month'].astype(str) + '-' + df['ETA_Day'].astype(str) + ' ' + df['ETA_Hour'].astype(str) + ':00:00')
df.set_index('Datetime', inplace=True)
# 선형 보간
df[columns_to_interpolate] = df[columns_to_interpolate].interpolate(method = 'time', limit_direction = 'both', limit_area = 'inside')
🧐 참고
▶︎ method='linear'
- 시간에 관계 없이 데이터 간의 선형 보간을 수행
- 시계열 데이터의 간격과 순서를 고려하지 않고 데이터 간의 선형 보간만을 수행하므로 시간 간격이 불규칙하거나 순서가 역순인 경우에도 동일한 방식으로 보간함
▶︎ method='time'
- 시계열 데이터를 기반으로 한 선형 보간을 수행
(시계열 데이터를 더 잘 고려하여 선형 보간을 수행하며, 시간 간격과 순서에 따라 데이터를 적절하게 보간)
- 시계열 데이터의 간격과 순서를 고려하므로 시계열 데이터가 시간 순서대로 정렬되어 있고 간격이 균일한 경우, 시간에 따라 선형 보간이 이루어짐
- 시계열 데이터가 시간 간격이 불규칙하거나 데이터가 시간 순서대로 정렬되지 않은 경우에도 시간 기준으로 보간을 시도함
728x90
'Projects > ⛴️ Ship Waiting Time Prediction' 카테고리의 다른 글
| [선박 대기시간 예측] 시계열/선석 기반 EDA (0) | 2023.12.15 |
|---|---|
| [선박 대기시간 예측] 선박 기반 EDA (0) | 2023.12.15 |
| [선박 대기시간 예측] 2차 전처리 : 중복값 처리 (0) | 2023.12.15 |
| [선박 대기시간 예측] 1차 전처리 : PORT-MIS 항만 데이터 결합 (2) | 2023.12.15 |
| [선박 대기시간 예측] 주제 선정 배경 (0) | 2023.12.15 |



