♻️ 순환경제 활성화를 위한 서울시 스마트 수거함 입지 선정

PCA 목적
- PCA Loading 값을 참고하여 Target Cluster(군집1)에 속하는 행정동 중 우선 설치가 필요한 행정동을 구분하기 위한 입지 지수를 선정하기 위함
PCA 절차
(1) 다중공선성 제거
- 높은 상관관계(VIF 10 이상)를 가지는 독립변수를 제거
- 상관계수(히트맵) 교차 확인
x_features = ['1인가구_비율','식품접객업','주점','연령대_2030_거주인구수_합', '주요경제활동인구_생활인구수', '수거함개수_당_거주인구수'] #'월평균_총생활인구수', '수거함_결핍률', '주점']
# x_features에 대한 VIF 계산을 위해 상수(intercept) 열을 추가
x_features_with_const = sm.add_constant(df[x_features])
# VIF 계산
vif_data = pd.DataFrame()
vif_data["Variable"] = x_features_with_const.columns
vif_data["VIF"] = [variance_inflation_factor(x_features_with_const.values, i) for i in range(x_features_with_const.shape[1])]
vif_data.T

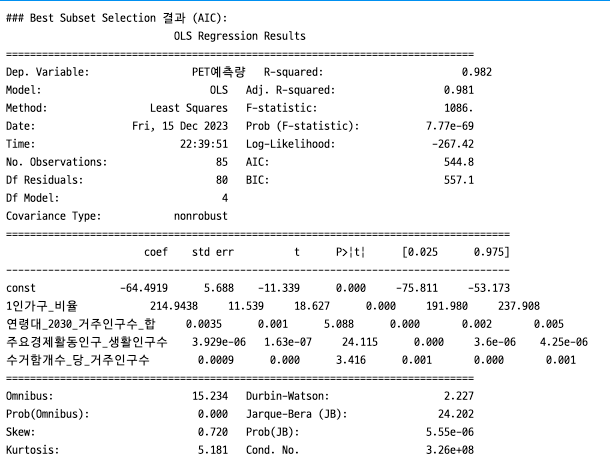
(2) Feature Selection 👉 Best Subset Selection
- Best Subset Selection : 가능한 모든 변수 조합을 생성하여 모델 성능 평가
- 초기 변수가 5개 이하로 많지 않았으므로, AIC를 변수 선택 시 유의하게 봄
- 선택된 변수 결과 : [1인가구_비율, 연령대_2030_거주인구수_합, 주요경제활동인구_생활인구수]
- 분석자 판단에 의한 핵심 변수 추가 : 수거함 개수 당 거주인구수

import itertools
import statsmodels.api as sm
import numpy as np
# 종속 변수 설정
y = df['PET예측량']
# 독립 변수 리스트 (const 를 제외한 변수들)
independent_variables = vif_data.iloc[1:, 0].tolist()
# 최적 모델 초기화
best_model = None
best_model_summary = None
best_aic = float('inf')
best_bic_model = None
best_bic_model_summary = None
best_bic = float('inf')
# Best Subset Selection
for k in range(1, len(independent_variables) + 1):
for subset in itertools.combinations(independent_variables, k):
X_subset = df[list(subset)]
X_subset = sm.add_constant(X_subset)
model = sm.OLS(y, X_subset).fit()
aic = model.aic
bic = model.bic
if aic < best_aic:
best_aic = aic
best_aic_model = model
best_aic_model_summary = model.summary()
if bic < best_bic:
best_bic = bic
best_bic_model = model
best_bic_model_summary = model.summary()
print("### Best Subset Selection 결과 (AIC):")
print(best_aic_model_summary)
(3) PCA로 입지 지수 개발 👉 제 1 주성분의 Loading 값을 입지식의 가중치(계수)로 사용
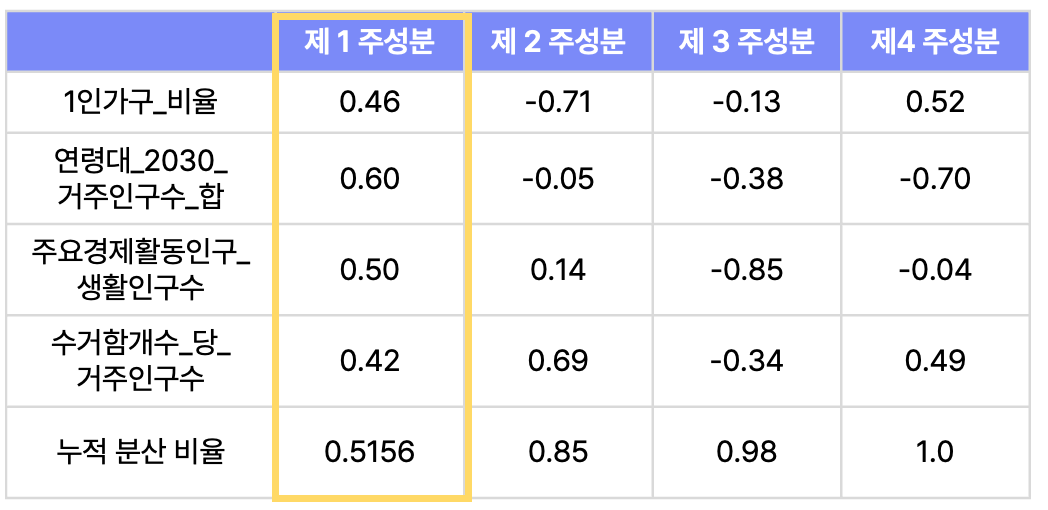
- PCA 수행시 Min-Max Scaling 적용 : 서로 다른 단위와 범위의 Feature를 비교하기 위해 최솟값 0, 최댓값 1로 변환
- SCORE = 1인가구_비율 x 0.46 + 연령대_2030_거주인구수_합 x 0.60 + 주요경제활동인구_생활인구수 x 0.50 + 수거함개수_당_거주인구수 x 0.42
# pca 수행
from sklearn.decomposition import PCA
from sklearn.preprocessing import MinMaxScaler
for_pca = ['1인가구_비율', '연령대_2030_거주인구수_합', '주요경제활동인구_생활인구수', '수거함개수_당_거주인구수']
pre_pca = df[for_pca]
# 스케일링
scaler = MinMaxScaler()
pre_pca = scaler.fit_transform(pre_pca)
pre_pca = pd.DataFrame(pre_pca)
# PCA 모델 생성
pca = PCA()
# 데이터를 PCA 모델에 fitting
pca.fit(pre_pca)
# 개별 주성분의 설명 분산 비율 출력
explained_variance_ratio = pca.explained_variance_ratio_
print("## 개별 주성분의 설명 분산 비율:\n", explained_variance_ratio)
# 누적 분산 비율 출력
cumulative_variance_ratio = np.cumsum(pca.explained_variance_ratio_)
print("## 누적 분산 비율:\n", cumulative_variance_ratio, '\n')
# 주성분(PC) 확인
principal_components = pca.components_
# 주성분의 Loadings 확인
loadings = pca.explained_variance_ratio_
# 주성분과 Loadings 출력
for i, (pc, loading) in enumerate(zip(principal_components, loadings), 1):
print(f'주성분 {i}: {pc} (Explained Variance: {loading:.2f})')
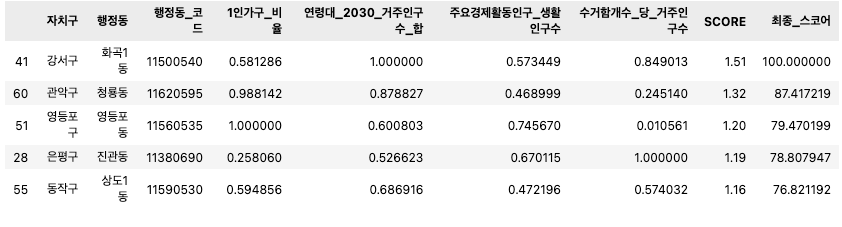
(4) Target 군집 내 행정동별 입지 지수(SCORE) 도출 👉 강서구 화곡1동 선정

# 행정동 데이터 MinMax스케일링
fin_features = ['자치구', '행정동', '행정동_코드', '1인가구_비율', '연령대_2030_거주인구수_합', '주요경제활동인구_생활인구수', '수거함개수_당_거주인구수']
df = df[fin_features]
scaler = MinMaxScaler()
df.iloc[:, 3:] = scaler.fit_transform(df.iloc[:, 3:])
df['SCORE'] = df['1인가구_비율']*0.46 + df['연령대_2030_거주인구수_합']*0.60 + df['주요경제활동인구_생활인구수']*0.50 + df['수거함개수_당_거주인구수']*0.42
df['SCORE'] = np.round(df['SCORE'], 2)
df['최종_스코어'] = df['SCORE'] / 1.510000 * 100
df.sort_values(by='최종_스코어', ascending = False).head()
728x90
'Projects > Bigdata Campus 공모전' 카테고리의 다른 글
| [스마트 수거함 입지 선정] 5. Target 행정동 수거함 입지 선정 (2) | 2023.12.19 |
|---|---|
| [스마트 수거함 입지 선정] 3. 행정동 군집화(K-means Clustering) (1) | 2023.12.19 |
| [스마트 수거함 입지 선정] 2. 행정동 PET 배출량 도출 (0) | 2023.12.19 |
| [스마트 수거함 입지 선정] 1. 주제 선정 배경 및 개요 (0) | 2023.12.19 |



