튜토리얼 데이터셋
아래 링크 경로를 통해 데이터셋을 받아올 수 있다 😊
처음부터 차근차근 코드를 작성하면 똑같은 결과물을 만들 수 있다
'https://raw.githubusercontent.com/dataprofessor/data/master/iris.csv'
결과물
데이터 분석을 해봤다면 누구나(?) 알 듯한 Iris data 를 가지고, 머신러닝 분류 모델을 앱으로 개발해보자.
스트림릿을 활용하여, 다음과 같은 대시보드를 만드는 것이 목표이다.
[참고] 스트림릿 앱을 가상으로 확인할 수 있는 경로는 다음과 같다(터미널에서 실행)
$ streamlit run app.py(파이썬 파일명)
스트림릿 시작하기
- 가상환경에 접속하기
- Vs code 를 열고, app.py 와 같이 파이썬 파일을 생성
- 아래와 같이 필요한 라이브러리를 임포트 : 데이터를 읽고 가공하는 pandas, streamlit, 모델링에 필요한 sklearn 등
import streamlit as st
import plotly.express as px
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from st_pages import Page, show_pages, add_page_title, show_pages
import warnings
warnings.filterwarnings('ignore')
페이지 정보 작성하기 (st.set_page_config)
- 대시보드 페이지의 정보를 요약해서 적어줄 수 있다
- 페이지 이름, 아이콘, 레이아웃, 사이드바를 디폴트로 열어둘 것인지 등을 설정한다.
# Page configuration
st.set_page_config(
page_title='Simple Prediction App',
page_icon='🌷',
layout='wide',
initial_sidebar_state='expanded'
)
앱 타이틀 작성하기 (st.title)
- 메인 화면 최상단에 등장할 앱 타이틀 작성
- st.title( ) 을 사용
# title of app
st.title('🌷 Simple Prediction App')
데이터셋 가져오기
- 판다스 라이브러리에서 데이터를 불러오는 방식과 동일하다
- st.write()를 이용하여 데이터프레임을 출력할 수 있다.
df = pd.read_csv('https://raw.githubusercontent.com/dataprofessor/data/master/iris.csv')
st.write(df)
사이드바 위젯 만들기
- 네 개 컬럼 값을 조정하며 예측 결과를 확인하고자 하는 것이 본 튜토리얼의 목표이다.
- 따라서 네 개 값을 조정할 수 있는 슬라이더를 사이더 바에 만들어보자.
- st.sidebar.subheader()로 사이드바 제목을 작성
- st.sidebar.slider() 로 사이드바 안에 슬라이더 생성 👉 (슬라이더이름, 최솟값, 최댓값, 초기설정값) 순으로 세팅
# input widgets
st.sidebar.subheader('Input Features')
sepal_length = st.sidebar.slider('Sepal length', 4.3, 7.9, 5.8)
sepal_width = st.sidebar.slider('Sepal width', 2.0, 4.4, 3.1)
petal_length = st.sidebar.slider('Petal length', 1.0, 6.9, 3.8)
petal_width = st.sidebar.slider('Petal width', 0.1, 2.5, 1.2)
예측 모델 생성하기
- 예측모델 생성을 위해 독립변수와 종속변수를 분리
- train, test 셋을 나누기
- 모델 생성하고 학습시키기
- 학습한 모델로 예측하기 👉 이때 예측할 때 들어갈 변수는 위에서 생성한 네 개 컬럼명을 입력
# Separate X and y
X = df.drop('Species', axis=1)
y = df.Species
# Data Splitting
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Model building
rf = RandomForestClassifier(max_depth=2, max_features=4, n_estimators=200, random_state=42)
rf.fit(X_train, y_train)
# Apply Model to make predictions
y_pred = rf.predict([[sepal_length, sepal_width, petal_length, petal_width]])
st.write(y_pred)
간단한 EDA_ 아이리스 종에 따른 4개 컬럼 평균 계산
- st.subheader() 로 서브 제목 생성
- 데이터 프레임을 groupby 하여, species를 기준으로 평균 내서 변수에 저장(groupby_species_mean)
- 해당 변수를 출력
# print EDA
st.subheader('Brief EDA')
st.write('The data is grouped by the class and the variable mean is computed for each class.')
groupby_species_mean = df.groupby('Species').mean()
st.write(groupby_species_mean)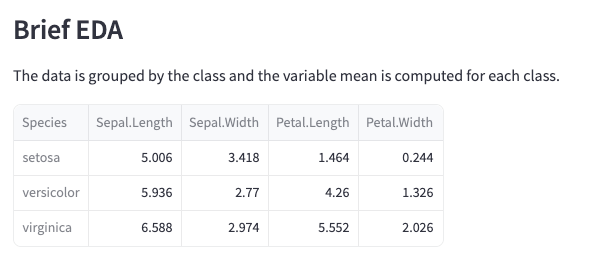
슬라이더에 Input 한 컬럼 값을 데이터프레임으로 출력하기
# print input Features
input_feature = pd.DataFrame([[sepal_length, sepal_width, petal_length, petal_width]],
columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'])
st.write(input_feature)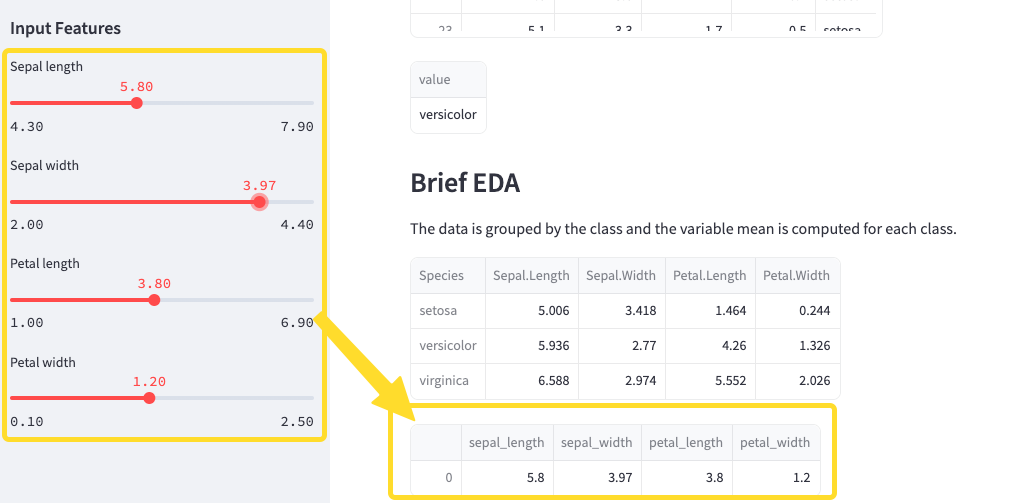
예측 결과값을 metric으로 출력
- st.metric() 사용하여 깔끔하게 출력
- y_pred(예측값)의 0번째 값(첫번째 값)을 출력
st.subheader('Output')
st.metric('Predicted class', y_pred[0], '')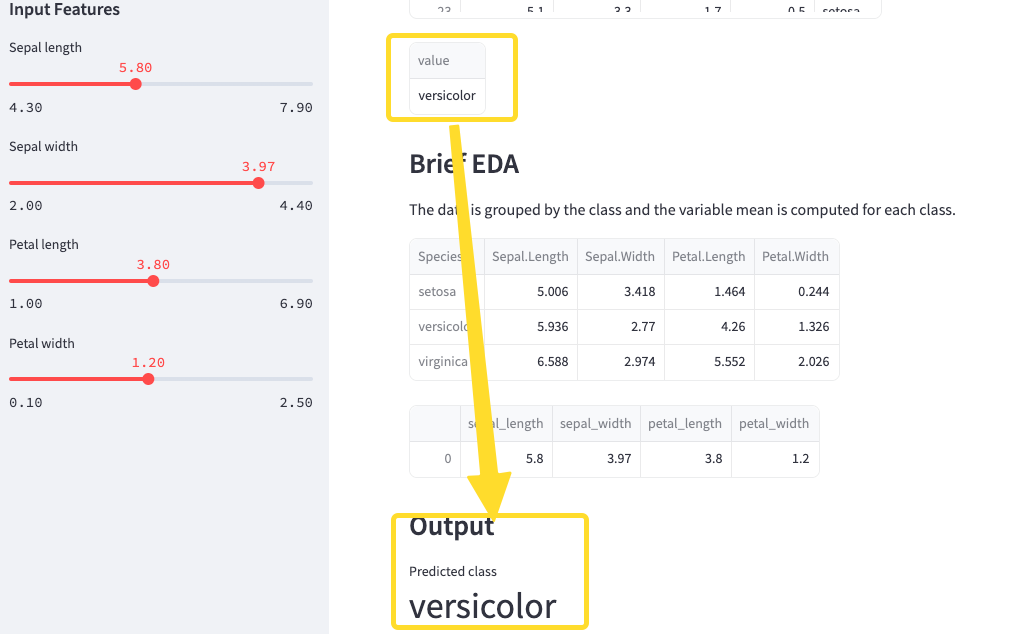
728x90
'Streamlit' 카테고리의 다른 글
| streamlit 배포 준비(2) (0) | 2023.09.01 |
|---|---|
| streamlit 배포 준비(1) (0) | 2023.09.01 |
| [Streamlit] Session state란? (0) | 2023.08.01 |
| Streamlit 이란? (0) | 2023.07.31 |
| Streamlit 기본 문법(9) : 사이드바 & selectbox, tab 활용 (0) | 2023.07.28 |

