GridSearchCV

역할 ▶︎ 교차 검증을 기반으로 하이퍼 파라미터의 최적 값을 찾게 해줌
- 데이터 세트를 학습/테스트 세트로 자동 분할
- 하이퍼 파라미터 그리드에 기술된 파라미터를 순차적으로 적용
- 학습과 평가까지 수행
👉 즉, cross-validation을 위한 학습/테스트 세트로 자동으로 분할한 뒤, 하이퍼 파라미터 그리드에 기술된 모든 파라미터를 순차적으로 적용해 최적의 파라미터를 찾을 수 있게 해준다.

- 사이킷런은 GridSearchCV 를 이용해 Classifier나 Regressor와 같은 알고리즘에 사용되는 하이퍼 파라미터를 순차적으로 입력하면서 편리하게 최적의 파라미터를 도출할 수 있다
- 최고 성능을 가지는 파라미터 조합을 찾기 위해, 파라미터의 집합을 만들고 순차 적용하며 최적화를 진행할 수 있다
- cv가 3회라면, 개별 파라미터 조합마다 3개의 폴딩 세트를 3회에 걸쳐 학습/평가하고, 평균값으로 성능을 측정한다.
📑 예제
데이터 준비 & DecisionTreeClassifier 모델 인스턴스 생성
- train_test_split( ) : 학습 데이터와 테스트 데이터를 먼저 분리
- DecisionTreeClassifier( ) 적용하여 객체 생성
from sklearn.datasets import load_iris # 예제 데이터 불러오기
from sklearn.tree import DecisionTreeClassifier # 결정트리 머신러닝 알고리즘 중 하나
from sklearn.model_selection import train_test_split # 훈련 데이터 / 테스트 데이터
from sklearn.metrics import accuracy_score
from sklearn.tree import export_graphviz
from sklearn.model_selection import GridSearchCV
iris = load_iris()
iris_data = iris.data # 독립변수
iris_label = iris.target # 종속변수
# 0은 setosa, 1은 versicolor 2는 virginica 품종으로 구분
x_train, x_test, y_train, y_test = train_test_split(
iris_data # 독립변수
, iris_label # 종속변수
, test_size=0.2
, random_state=2023
)
# DecisionTreeClassifier 객체 생성
dtree = DecisionTreeClassifier()
📑 하이퍼 파라미터 지정 & 학습
- 테스트할 하이퍼 파라미터 세트는 딕셔너리 형태로 지정 : 하이퍼 파라미터 명칭(문자열 Key값), 하이퍼 파라미터의 값(리스트형)
- cv : 교차 검증을 위해 분할되는 학습/테스트 세트의 개수
- refit : 디폴트가 True 이며, True 로 생성시 가장 최적의 하이퍼 파라미터를 찾은 뒤 입력된 estimator 객체를 해당 하이퍼파라미터로 재학습 시킴
fit() 으로 학습 수행 시,
👉 cv에 기술된 폴딩 세트로 분할해 param_grid에 기술된 하이퍼 파라미터를 순차적으로 변경하면서 학습/평가 진행
👉 그 결과를 cv_results_속성에 기록
- cv_results_ 는 gridsearchcv의 결과 세트로, 딕셔너리 형태로 key값과 리스트 형태의 value 값을 가짐
- 이를 pandas dataframe으로 변환하면 내용을 더 쉽게 볼 수 있음
- 최고 성능을 나타낸 하이퍼 파라미터 값 : best_params_ 속성
- 최고 성능을 나타냈을 때 평가 결과 값 : best_score_ 속성
parameters = {'max_depth':[1, 2, 3], 'min_samples_split':[2, 3]}
grid_dtree = GridSearchCV(dtree, param_grid = parameters, cv = 3, refit = True)
grid_dtree.fit(x_train, y_train)
print('GridSearchCV 최적 파라미터: ', grid_dtree.best_params_)
print( f'GridSearchCV 최고 정확도:{grid_dtree.best_score_}')
scores_df = pd.DataFrame(grid_dtree.cv_results_)
scores_df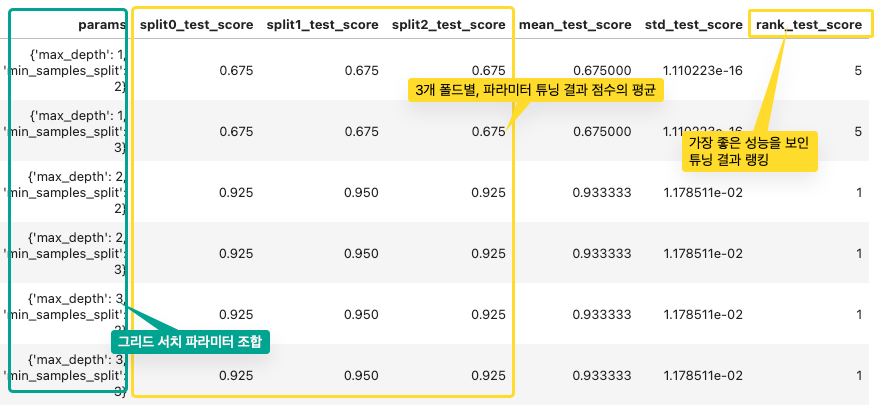
📑 모델 성능을 테스트
- refit = True 설정을 했으므로, GridSearchCV가 최적 성능을 나타내는 하이퍼 파라미터 Estimator를 학습해서, best_estimator_ 속성에 저장
# GridSearchCV의 refit으로 이미 학습된 estimator 반환
estimator = grid_dtree.best_estimator_
pred = estimator.predict(X_test)
print('테스트 데이터 세트 정확도: {0:.4f}' .format(accuracy_score(y_test, pred)))
----(결과)------
테스트 데이터 세트 정확도: 0.9667
- GridSearchCV 객체의 fit()을 수행하면 최고 성능을 나타낸 하이퍼 파라미터 값과 그때의 평가 결과 값이 각각 best_params_, best_score_ 속성에 기록됨
- 학습된 best_estimator_를 이용해서 테스트 데이터 세트에 대해 예측 및 성능 평가 가능
- 이렇게 학습 데이터를 GridSearchCV를 이용해 최적 하이퍼 파라미터 튜닝을 수행한 뒤에 별도의 테스트 세트에서 이를 평가하는 것이 일반적인 머신러닝 모델 적용 방법임
728x90
'Machine Learning > scikit-learn' 카테고리의 다른 글
| [이진 분류_성능 평가 지표] 정밀도 / 재현율 (0) | 2023.08.20 |
|---|---|
| [분류_성능 평가 지표] 정확도와 오차 행렬(이진 분류) (0) | 2023.08.18 |
| [교차 검증] Stratified K 폴드 (0) | 2023.08.17 |
| [교차 검증] K-폴드 교차 검증 (0) | 2023.08.17 |
| [데이터 전처리] MinMaxScaler를 이용한 데이터 정규화 예제 (0) | 2023.08.17 |



