
✔ Process Check
지금까지 이상치와 결측치 등을 점검하는 EDA를 마친 후, 파생변수를 생성했다.
이제 모델링을 통해 유의미한 파생변수를 선택하고, 최종 모델링에 필요한 변수를 채택하는 과정이 남았다.
이를 위해 아래와 같이 LightGBM + K-fold CV + RandomSearch 을 활용한 모델링 베이스라인 코드가 완성되었다.
1. 라이브러리 불러오기
import numpy as np
import pandas as pd
import lightgbm as lgb
from lightgbm import LGBMRegressor
from sklearn.model_selection import KFold, train_test_split, RandomizedSearchCV
from sklearn.metrics import mean_squared_error, mean_absolute_error
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.font_manager as fm
import joblib
import os▶︎ 폰트 설정
#font 오류 수정
font_list = fm.findSystemFonts()
font_name = None
for font in font_list:
if 'AppleGothic' in font:
font_name = fm.FontProperties(fname=font).get_name()
plt.rc('font', family=font_name)
2. 모델링용 데이터 불러오기
- 모델링을 위해 전처리를 완료한 데이터셋을 불러온다.
# 데이터 불러오기 및 전처리
data = pd.read_csv('./data/골목_model용.csv')▶︎ X, Y 변수 분리
- 독립변수 : 모델링에 사용할 변수로, 연도, 분기, 상권코드, 상권코드명, 시간대 및 매출을 제외한 나머지 변수
- 종속변수 : 편의점 매출
# 데이터 로드(실제 데이터셋 가져오기)
X = data.iloc[:, 5:]
y = data.iloc[:, 0]
3. K-fold 교차 검증 & lightGBM 모델 초기 매개변수 설정
- 데이터셋의 크기를 고려하여 k 값을 10으로 설정하여 k-fold 진행
- 기본적인 LightGBM 파라미터 설정 완료
# k-폴드 교차 검증
num_folds = 10
kf = KFold(n_splits= num_folds, shuffle=True, random_state=42)
# LightGBM 모델 초기화
params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'rmse',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9
}▶︎ 특성 중요도 리스트 / 결과 스코더 리스트 생성
- 모델링 결과인 (1) 특성 중요도와 (2) 폴드별 결과 스코어를 저장할 리스트를 생성
# 특성 중요도 리스트 초기화
feature_importance_list = []
# 결과 스코어
rmse_scores = [] # RMSE 스코어를 저장할 리스트
mae_scores = [] # MAE 스코어를 저장할 리스트
best_params_list = [] # 각 fold에서의 최적 파라미터를 저장할 리스트
▶︎ 데이터 분할(train, test)
- train 용, test 용 데이터를 우선 분리
- (이후, train 데이터를 k-fold에서 다시한번 Train, validation용으로 나눌 예정)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
▶︎ RandomSearch 하이퍼 파라미터 종류 & 범위 설정
- 모델 최적화를 위한 하이퍼 파라미터 튜닝
- 주요한 하이퍼 파라미터를 선정하고, RandomSearch를 위해 범위 설정해 줌
param_dist = {
'objective': ['regression'],
'metric': ['mse'],
'num_leaves': list(range(7, 64)), # 7부터 63까지
'learning_rate': [0.01, 0.02, 0.03, 0.04, 0.05], #0.01부터 0.05까지
'n_estimators': list(range(200, 301)), # 200부터 300까지
'early_stopping_rounds': list(range(40, 51)) # 40부터 50까지
}
4. K-fold 교차 검증 10회 수행 👉 모델링과 학습 과정
- for문으로 K-fold의 k값 만큼 train, valiation 데이터 셋을 나누고
- lightGBM 용 데이터 셋을 지정
- RandomSearchCV() 모델을 생성하고, lightGBMRegressor 모델 지정, 세팅한 하이퍼 파라미터 범위 지정
- 학습 후, 최적 파라미터 도출
- 최적 파라미터로 모델 재적합 & 재학습
- valid 데이터로 예측 및 평가 결과 도출, 리스트에 저장
# K-Fold 교차 검증 수행
for train_index, val_index in kf.split(X_train):
# train, validation 데이터셋트 분리(fold 별)
X_train_kf, X_val_kf = X.iloc[train_index], X.iloc[val_index]
y_train_kf, y_val_kf = y.iloc[train_index], y.iloc[val_index]
# lightGBM용 데이터셋 지정
train_data = lgb.Dataset(X_train_kf, label=y_train_kf)
val_data = lgb.Dataset(X_val_kf, label=y_val_kf, reference=train_data)
# RandomSearch를 사용한 LightGBM 모델 튜닝 준비
random_search = RandomizedSearchCV(
lgb.LGBMRegressor(),
param_distributions=param_dist,
n_iter=10,
scoring='neg_mean_squared_error',
cv=kf,
random_state=42,
n_jobs=-1,
verbose=1
)
# LightGBM 평가용 데이터셋 지정
evals = [(X_train_kf, y_train_kf),(X_val_kf, y_val_kf)]
# RandomSearch(LightGBM) 학습
random_search.fit(X_train_kf, y_train_kf, eval_set = evals, eval_metric='rmse')
# 최적 파라미터 도출
best_params = random_search.best_params_
# bst 변수에 최적 파라미터로 모델 재학습
bst = lgb.LGBMRegressor(**best_params)
bst.fit(X_train_kf, y_train_kf,
eval_set=evals,
eval_metric='rmse',
verbose=False)
#Feature importance 계산, 리스트에 저장
feature_importance = bst.feature_importances_
feature_importance_list.append(feature_importance)
# 모델 평가 (RMSE) 및 결과 리스트에 저장
y_pred = bst.predict(X_val_kf)
mse = mean_squared_error(y_val_kf, y_pred)
rmse = np.sqrt(mean_squared_error(y_val_kf, y_pred))
mae = mean_absolute_error(y_val_kf, y_pred)
rmse_scores.append(rmse)
mae_scores.append(mae)
best_params_list.append(best_params)
▶︎ 교차 검증 결과 종합
- np.mead() 으로 폴드별 교차검증 결과를 평균내기
- RMSE, MAE 평균 결과값 확인
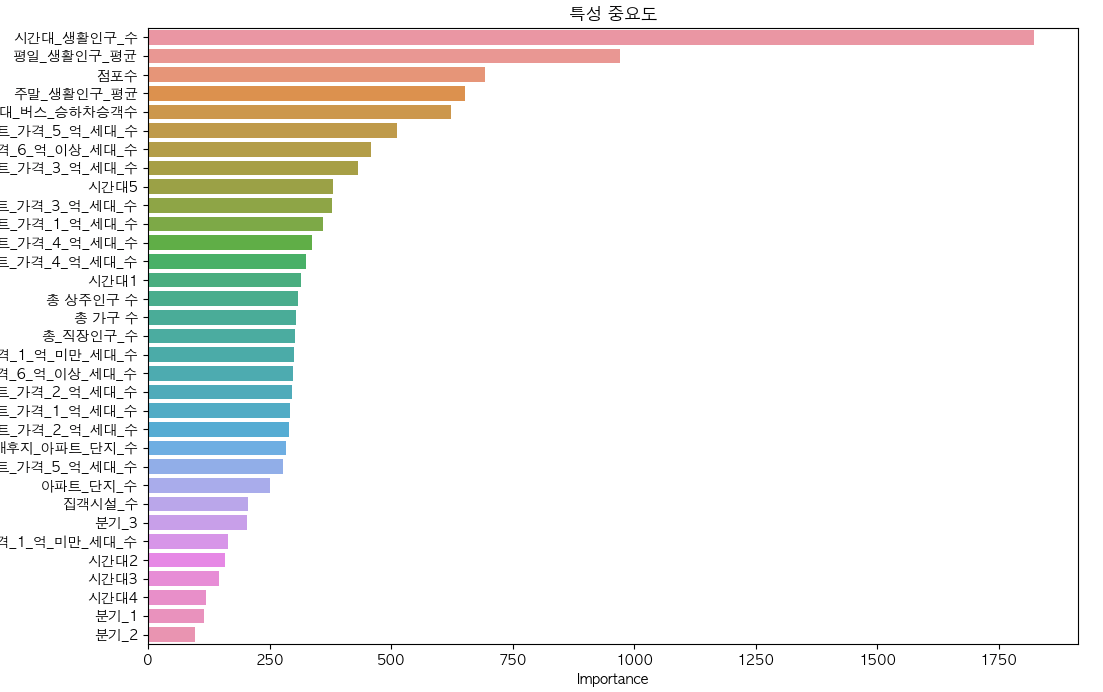
- 특성 중요도 결과도 평균 내기
- 특성 중요도 결과를 특성명과 함께 시각화 : 데이터프레임 생성 후, 내림차순 정렬
- 가장 높은 특성 중요도를 가진 피쳐부터 확인 가능
# 교차 검증 결과 출력
mean_rmse = np.mean(rmse_scores)
mean_mae = np.mean(mae_scores)
print(f'평균 RMSE: {mean_rmse}')
print(f'평균 MAE: {mean_mae}')
# 특성 중요도 평균 계산
average_feature_importance = np.mean(feature_importance_list, axis=0)
# 특성 이름
feature_names = X.columns
# 중요도를 특성 이름과 함께 출력
feature_importance_df = pd.DataFrame({'Feature': feature_names, 'Importance': average_feature_importance})
feature_importance_df = feature_importance_df.sort_values(by='Importance', ascending=False)
print(feature_importance_df)
# 특성 중요도 시각화
plt.figure(figsize=(12, 8))
sns.barplot(x='Importance', y='Feature', data=feature_importance_df)
plt.title('특성 중요도')
plt.show()
▶︎ 최적 하이퍼 파라미터 확인 및 모델 저장
# K-fold 교차 검증에서 얻은 최적 파라미터 출력(폴드별)
print("K-fold 교차 검증을 위한 최적 하이퍼파라미터:")
for i, params in enumerate(best_params_list):
print(f'Fold {i + 1}: {params}')
# 모델 저장
if not os.path.exists("models"):
os.mkdir("models")
model_file = open("models/gm_model.pkl", "wb")
joblib.dump(bst, model_file) # Export
model_file.close()
👉 이렇게 구축한 베이스라인 모델링 코드로, 시간대별 편의점 매출 예측을 수행하며
이를 streamlit 대시보드에 구현하는 작업이 이어진다.
728x90
'Projects > 🏪 Convenience Store Location Analysis' 카테고리의 다른 글
| [선박 대기시간 예측] 2차 전처리 : 중복 행 정리 (0) | 2023.11.15 |
|---|---|
| [Mini Project] 10. 매출의 분포 확인 (+ 이상치 제거 후 모델 성능 체크) (0) | 2023.09.18 |
| [Mini Project] 9. 모델링 및 피쳐(파생변수) 선택 (0) | 2023.09.18 |
| [프로젝트 스터디] 회귀 문제 평가 지표 (0) | 2023.09.14 |
| [프로젝트 스터디] Feature Scaling (Min-Max scaling) (0) | 2023.09.14 |



