Kaggle Survey Data 시각화
0. 데이터 가져오기
import pandas as pd
df = pd.read_csv('./data/kaggle/kaggle_survey_2021/kaggle_survey_2021_responses.csv')
df.head()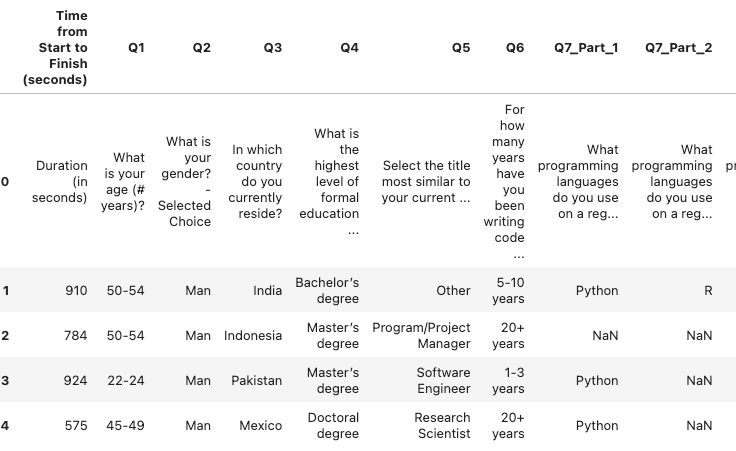
1. 원하는 데이터 추출
#질문데이터 한 줄만 따로 뽑기
questions = df.iloc[0, :].T
#나머지 데이터(인덱스 1번 이후)정리
df = df.iloc[1:, :].reset_index(drop=True)
#1번 설문문항의 답을 따로 시리즈로 뽑아내기
q1_df = df['Q1'].value_counts()
#1번 질문이 뭐였는지 간단히 확인
questions.Q1
>>'What is your age (# years)?'
2. 그래프 시각화
fig = go.Figure()
fig.add_trace(go.Bar(name = "Age", x = q1_df.index, y = q1_df.values))
fig.show()👉 아래와 같이 그래프가 내림차순으로 나타난다.
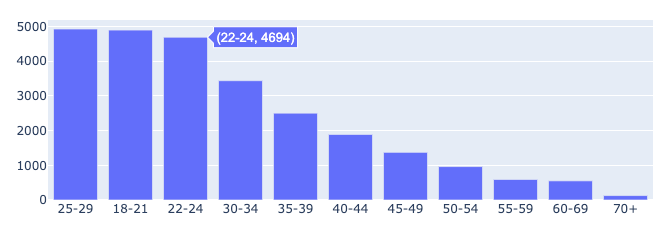
➡ 이를 x값의 오름차순 기준으로 보고싶다면?
#기본 그래프
fig = go.Figure()
fig.add_trace(go.Bar(name = "Age", x = q1_df.index, y = q1_df.values))
print(fig.show('json'))
#styling update
CATEGORY_ORDER = ["18-21", "22-24", "25-29", "30-34", "35-39", "40-44", "45-49", "50-54", "55-59", "60-69", "70+"]
fig.update_layout(plot_bgcolor = 'white', font = dict(color = "#333333"),
title = dict(text = "Title"),
xaxis = dict(title = "your X-AXIS TITLE", linecolor = "#21DBAA", categoryorder = "array", categoryarray = CATEGORY_ORDER),
yaxis = dict(title = "your Y-AXIS TITLE", linecolor = "#DB9021")
)
#print(fig.show('json'))
fig.show()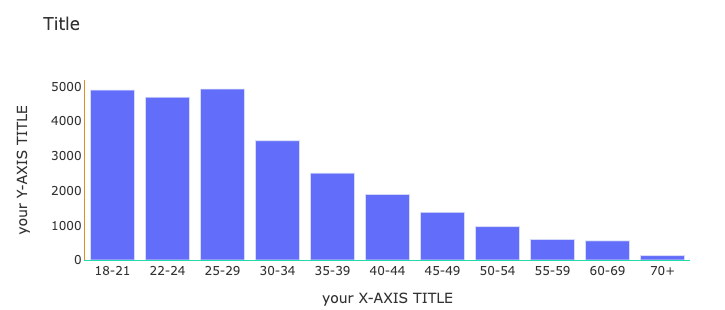
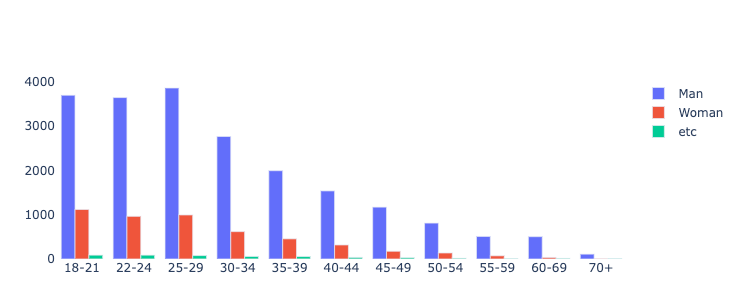
🔰 추가 예제 : 성별/연령별 사람수 시각화
- 전체 데이터에서 원하는 부분 추출
- 특정 컬럼의 값들을 변경(replace함수 사용)
- Q1, Q2 를 기준으로 groupby 하여, 각 그룹의 개수를 size() 로 확인, 컬럼명은 "Count"로 수정
q1_q2_df = df.loc[:, ["Q1", "Q2"]].replace({'Prefer not to say':'etc', 'Nonbinary':"etc", "Prefer to self-describe": "etc"})
q1_q2_df = q1_q2_df.groupby(['Q2','Q1']).size().reset_index().rename(columns = {0:"Count"})
q1_q2_df.head()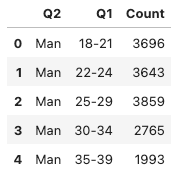
#그래프 시각화(반복문 사용)
fig = go.Figure()
for gender, group in q1_q2_df.groupby('Q2'):
fig.add_trace(go.Bar(x = group['Q1'], y = group['Count'], name = gender))
fig.update_layout(barmode='group', plot_bgcolor = 'white')
fig.show()
728x90
'Python > Data Visualization' 카테고리의 다른 글
| [Kaggle 데이터 활용] 여러 개의 그래프 한번에 그리기(2) 심화 (0) | 2023.08.10 |
|---|---|
| [Kaggle 데이터 활용] 여러 개의 그래프 한번에 그리기(2) 기초 (0) | 2023.08.10 |
| [Kaggle 활용] 인도/미국 연봉 비율 비교 EDA 총정리 예제 (0) | 2023.08.10 |
| [Plotly] 그래프 수정가능한 옵션 보기 (0) | 2023.08.10 |
| [Plotly] 시작하기 : 막대그래프 예제 (0) | 2023.08.10 |



