Kaggle 2021년 survey 데이터 시각화
4개 국가 별, 가장 많이 쓰이는 클라우드 서비스 시각화하여 비교하기
라이브러리 import
import plotly.graph_objects as go
import plotly.figure_factory as ff #대화형 시각화 라이브러리
데이터 불러오고, 간단히 가공하기
df21 = pd.read_csv("./data/kaggle/kaggle_survey_2021/kaggle_survey_2021_responses.csv")
questions = df21.iloc[0, :].T
df21 = df21.iloc[1:, :]간단히 데이터 확인
print(questions['Q28'])
print(questions['Q29_A_Part_1'])Of the cloud platforms that you are familiar with, which has the best developer experience (most enjoyable to use)? - Selected Choice
Do you use any of the following cloud computing products on a regular basis? (Select all that apply) - Selected Choice - Amazon Elastic Compute Cloud (EC2) 위 질문에 대한 답으로 들어온 데이터가 이렇게 자유분방(?)한걸 확인할 수 있다. >> 유사한 질문, 답변 데이터 중복 문제
다양한 클라우드 서비스를 사용한다는 여러 응답들인데 이러한 두 질문(28, 29의 파트1 ~ 파트4)에 대한 답변 데이터를 정리해보자.
먼저, 유사한 질문인 Q29_A_part1~4 의 네 개 문항 답변을 정리해서 보도록 하자. 함수를 쓸 것이다.
sub_questions_count 함수
👉 주어진 질문 번호(question_num)와 파트 개수(part_num)를 기반으로 질문 목록을 생성
- 매개변수 : 질문 번호(question_num), 파트 번호(part_num), text 매개변수는 기본값이 False
- part_questions 라는 빈리스트 생성
- 만약 text가 "A" 또는 "B" 중 하나인 경우, 조건문 실행
- 조건이 참일 경우 :
- 문자열을 part_questions 라는 빈 리스트에 추가
- 예를 들어, question_num이 1이고 part_num이 4이며, text가 "A"인 경우: 'Q1_A_Part_1', 'Q1_A_Part_2', 'Q1_A_Part_3'이 part_questions에 추가됨
- 그 다음, Q1_A_OTHER'와 같은 형식의 추가적인 문자열을 part_questions에 추가
- 조건이 거짓일 경우 : "A" 또는 "B"가 아닌 다른 텍스트 경우
- 이 경우도 위와 동일하게 part_questions 리스트에 지정된 형식에 따라 문자열들을 추가
- 조건이 참일 경우 :
def sub_questions_count(question_num, part_num, text = False):
part_questions = []
if text in ["A", "B"]:
part_questions = ['Q' + str(question_num) + "_" + text + '_Part_' + str(j) for j in range(1, part_num)]
part_questions.append('Q' + str(question_num) + "_" + text + '_OTHER')
else:
part_questions = ['Q' + str(question_num) + '_Part_' + str(j) for j in range(1, part_num)]
part_questions.append('Q' + str(question_num) + '_OTHER')
위의 sub_questions_count 함수와 이어집니다
- categories와 counts 라는 빈 리스트를 생성 : 질문 카테고리와 각 카테고리에 속하는 질문 수를 저장할 용도
- part_questions 리스트의 각 요소에 대해 반복문 실행 :
- category = 데이터프레임 df의 i 열에서 가장 높은 빈도수를 가진 값
- val = df의 i 열에서 가장 높은 빈도수를 가진 값의 빈도
- category와 val 값을 각각 리스트에 저장
- 빈 데이터프레임 combined_df 생성
- combined_df에 Category와 Count 열 추가, 각 열에 categories와 counts 리스트 내용 넣기
- Count 열을 기준으로, combined_df 를 내림차순 정렬
- 정렬된 combined_df를 Return
# category count
categories = []
counts = []
for i in part_questions:
category = df[i].value_counts().index[0]
val = df[i].value_counts()[0]
categories.append(category)
counts.append(val)
combined_df = pd.DataFrame()
combined_df['Category'] = categories
combined_df['Count'] = counts
combined_df = combined_df.sort_values(['Count'], ascending = False)
return combined_df
- 앞서 정의한 sub_questions_count 함수 호출 : sub_questions_count(29, 4, "A")
- 29번 질문의 A파트에 대한 카테고리별 질문수를 계산하여 반환할 것
- 29번 하위의 4개 질문 각각에서 가장 많이 나온 답변과 그 수를 categories와 counts 리스트에 담는 것
- 결과 : combined_df

👀 이를 통해 29번의 A 문항과 연결된 1, 2, 3, 4 네 개 질문에서 핵심(각 문항별 가장 많이 응답된 클라우드 서비스와 그 수)만 뽑아 볼 수 있었다.
👉 이제 28번 문항의 결과를 4개 나라별로 시각화해서 살펴보자.
- df21['Q28'].value_counts()
- df21 데이터프레임의 Q28 컬럼에 있는 값들의 빈도를 반환 => 28번 질문에 대한 응답분포를 확인
sub_questions_count(29, 4, "A")
df21['Q28'].value_counts()
- Q5 컬럼에 있는 값들(직업) 중에서, 주어진 직업에 해당하는 데이터만 선택하여 df21 데이터프레임을 필터링
- Q3 컬럼에 있는 값들(나라) 중에서 일부 국가명을 변경(간결하게!)
- country_list 에 분석할 국가들을 나타내는 리스트 정의
- countries_df : country_list에 포함된 국가들에 해당하는 데이터만 선택한 데이터프레임 (4개 국가 데이터만 보고싶으니까)
- q3_q8 :
- 위에서 생성한 4개 국가 데이터를 국가와 28번 질문 열을 기준으로 그룹화
- 각 그룹 내 데이터 개수를 세어 count 열로 나타냄
df21 = df21[df21['Q5'].isin(['Student','Data Scientist','Software Engineer', 'Data Analyst', 'Machine Learning Engineer','Research Scientist'])]
df21['Q3'] = df21['Q3'].replace(['United States of America', 'South Korea'], ['USA', 'Korea']) # Change Name
country_list = ["USA", "China", "Japan", "Korea"]
countries_df = df21[df21['Q3'].isin(country_list)]
q3_q28 = countries_df.groupby(['Q3', 'Q28']).size().reset_index().rename(columns = {0:"Count"})

get_pnt 함수 : 데이터와 국가를 입력 받아, 해당 국가의 데이터를 가공하는 역할
- 입력한 데이터프레임에서 입력 국가에 해당하는 데이터만 추출하여 data_country 라는 데이터프레임 생성
- 방금 생성한 데이터프레임에 28번 질문 응답 분포 비율을 나타내는 컬럼 추가 => percentage 컬럼
- percentage 컬럼 값을 numpy 메서드를 써서 소수점 첫째자리까지 반올림하여 % 비율로 나타냄 => % 컬럼
- 이렇게 정리한 data_country 데이터프레임을 Return
+ 마지막으로 get_pnt 함수를 써서 4개 국가에 대한 data_country 데이터 프레임 만들기
def get_pnt(data, country):
data_country = data[data['Q3'] == country].reset_index(drop = True)
data_country['percentage'] = data_country["Count"] / data_country["Count"].sum()
data_country['%'] = np.round(data_country['percentage'] * 100, 1)
return data_country
usa_df = get_pnt(q3_q28, "USA")
china_df = get_pnt(q3_q28, "China")
japan_df = get_pnt(q3_q28, "Japan")
korea_df = get_pnt(q3_q28, "Korea")
🚩 최종 데이터 시각화
- 네 개 국가별로 사용하는 클라우드 서비스 비교하는 막대그래프 만들기
fig = make_subplots(rows = 2, cols = 2,
shared_xaxes=True, # Shared X Axes
shared_yaxes=True, # Shared Y Axes
vertical_spacing = 0.05,
subplot_titles=("USA with Q28", "China with Q28", "Japan with Q28", "Korea with Q28"), # title of each graph area
column_widths = [0.5, 0.5]) # size control
fig.add_trace(go.Bar(x = usa_df['Q28'],
y = usa_df['%'],
text = usa_df['%'].astype(str) + "%",
textposition='auto'),
row = 1, col = 1)
fig.add_trace(go.Bar(x = china_df['Q28'],
y = china_df['%'],
text = china_df['%'].astype(str) + "%",
textposition='auto'),
row = 1, col = 2)
fig.add_trace(go.Bar(x = japan_df['Q28'],
y = japan_df['%'],
text = japan_df['%'].astype(str) + "%",
textposition='auto'),
row = 2, col = 1)
fig.add_trace(go.Bar(x = korea_df['Q28'],
y = korea_df['%'],
text = korea_df['%'].astype(str) + "%",
textposition='auto'),
row = 2, col = 2)
fig.update_layout(height = 1000,
showlegend=False)
fig.show()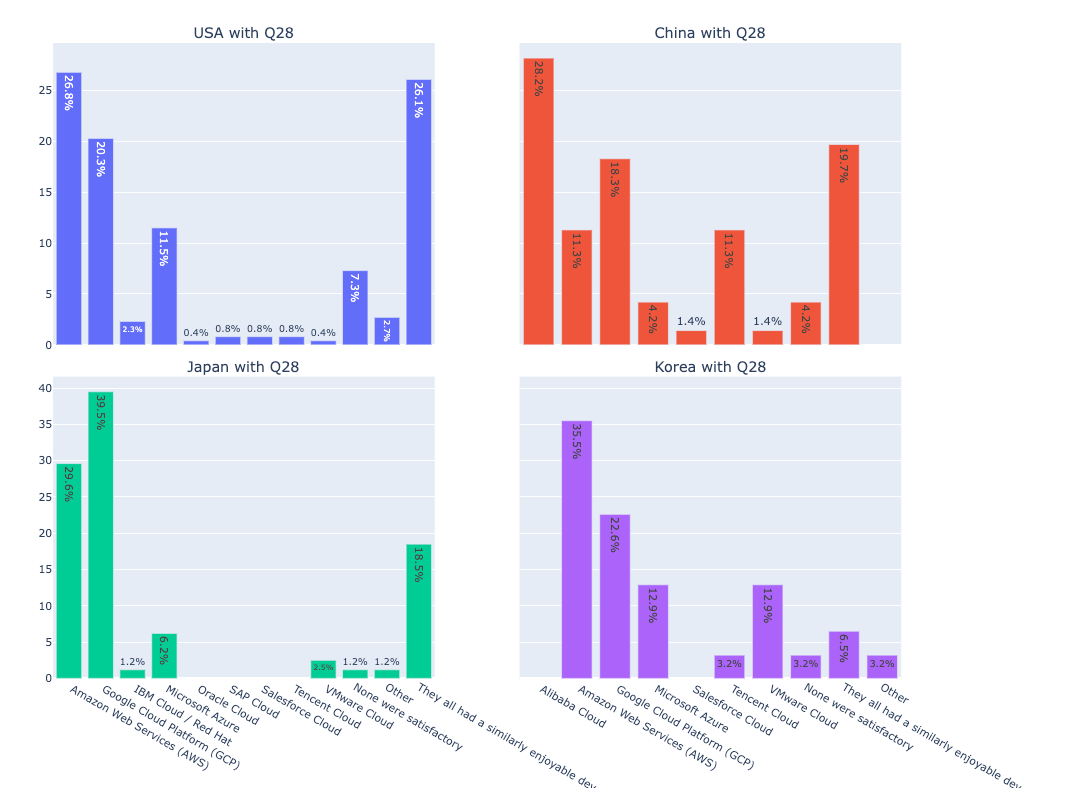
728x90
'Python > Data Visualization' 카테고리의 다른 글
| [구글 colab 데이터 시각화] 한글 폰트 설정 (0) | 2023.08.16 |
|---|---|
| [Kaggle 데이터 활용] 연도별 프로그래밍 언어의 사용성 추이 파악 (0) | 2023.08.10 |
| [Kaggle 데이터 활용] 여러 개의 그래프 한번에 그리기(2) 기초 (0) | 2023.08.10 |
| [Plotly] Kaggle Survey Data 시각화 기초 (0) | 2023.08.10 |
| [Kaggle 활용] 인도/미국 연봉 비율 비교 EDA 총정리 예제 (0) | 2023.08.10 |



