프로그래밍 언어 데이터 추출하여, 연도별 사용도 파악
2019년부터 2020년까지의 Kaggle Survey 데이터 활용
1. 데이터 불러오기
df_2021 = pd.read_csv("./data/kaggle/kaggle_survey_2021/kaggle_survey_2021_responses.csv")
df_2020 = pd.read_csv("./data/kaggle/kaggle_survey_2020/kaggle_survey_2020_responses.csv")
df_2019 = pd.read_csv("./data/kaggle/kaggle-survey-2019/multiple_choice_responses.csv")
df_2021.shape, df_2020.shape, df_2019.shape
2. 각 연도별로 사용하는 '프로그래밍 언어'의 고윳값 확인
print("2019:", df_2019['Q19'].unique().tolist())
print("2020:", df_2020['Q8'].unique().tolist())
print("2021:", df_2021['Q8'].unique().tolist())👉 결과
2019: ['What programming language would you recommend an aspiring data scientist to learn first? - Selected Choice', 'Python', nan, 'Java', 'R', 'SQL', 'C++', 'Other', 'C', 'MATLAB', 'TypeScript', 'Javascript', 'Bash']
2020: ['What programming language would you recommend an aspiring data scientist to learn first? - Selected Choice', 'Python', 'R', 'C++', 'SQL', nan, 'Java', 'MATLAB', 'C', 'Other', 'Javascript', 'Julia', 'Swift', 'Bash']
2021: ['What programming language would you recommend an aspiring data scientist to learn first? - Selected Choice', 'Python', 'SQL', 'R', 'MATLAB', 'C', 'Julia', nan, 'Other', 'C++', 'Javascript', 'Java', 'Bash', 'Swift']
3. 결과로 나온 프로그래밍 언어 중 확인하고 싶은 언어만 따로 정리
programming_list = ["Python", "R", "SQL", "Java", "C", "Bash", "Javascript", "C++"]
programming_df = pd.Series(programming_list)
- 각 연도별로 위에서 정리한 programming_list 에 해당되는 데이터로 업데이트하기
- 업데이트하고, 연도별 언어 고윳값 체크
df_2019 = df_2019[df_2019['Q19'].isin(programming_df)]
df_2020 = df_2020[df_2020['Q8'].isin(programming_df)]
df_2021 = df_2021[df_2021['Q8'].isin(programming_df)]
print("2019:", df_2019['Q19'].unique().tolist())
print("2020:", df_2020['Q8'].unique().tolist())
print("2021:", df_2021['Q8'].unique().tolist())👉 결과
2019: ['Python', 'Java', 'R', 'SQL', 'C++', 'C', 'Javascript', 'Bash']
2020: ['Python', 'R', 'C++', 'SQL', 'Java', 'C', 'Javascript', 'Bash']
2021: ['Python', 'SQL', 'R', 'C', 'C++', 'Javascript', 'Java', 'Bash']
4. 연도별 데이터에서 필요한 컬럼 추출, 통합
- 연도별 데이터에서 필요한 컬럼들만 추출해서 정리하기
- 컬럼명 맞추고, 수정해서 일관되게 만들기
- 각 연도별 데이터프레임을 합치기
q3_q5_q19_2019 = df_2019.loc[:, ['Q3', 'Q5', 'Q19']]
q3_q5_q19_2019 = q3_q5_q19_2019.rename(columns = {'Q19': 'Q8'}) # To match with other datasets
q3_q5_q8_2020 = df_2020.loc[:, ['Q3', 'Q5', 'Q8']]
q3_q5_q8_2021 = df_2021.loc[:, ['Q3', 'Q5', 'Q8']]
q3_q5_q19_2019['year'] = '2019'
q3_q5_q8_2020['year'] = '2020'
q3_q5_q8_2021['year'] = '2021'
final_df = pd.concat([q3_q5_q19_2019, q3_q5_q8_2020, q3_q5_q8_2021])
final_df.head()
- 위에서 도출된 데이터프페임에서 year과 Q8 컬럼을 기준으로 그룹화
- 각 그룹의 value 를 합산 > count 컬럼으로 추가
import numpy as np
year_q5_q8 = final_df.groupby(['year', 'Q8']).size().reset_index().rename(columns = {0:"Count"})
year_q5_q8
- 연도별로 데이터 정리
- 프로그래밍 언어별 사용 비율 컬럼 추가
import numpy as np
year_q5_q8 = final_df.groupby(['year', 'Q8']).size().reset_index().rename(columns = {0:"Count"})
# 2019
q8_2019 = year_q5_q8[year_q5_q8['year'] == "2019"].reset_index(drop = True)
q8_2019['percentage'] = q8_2019["Count"] / q8_2019["Count"].sum()
q8_2019['%'] = np.round(q8_2019['percentage'] * 100, 1)
# 2020
q8_2020 = year_q5_q8[year_q5_q8['year'] == "2020"].reset_index(drop = True)
q8_2020['percentage'] = q8_2020["Count"] / q8_2020["Count"].sum()
q8_2020['%'] = np.round(q8_2020['percentage'] * 100, 1)
# 2021
q8_2021 = year_q5_q8[year_q5_q8['year'] == "2021"].reset_index(drop = True)
q8_2021['percentage'] = q8_2021["Count"] / q8_2021["Count"].sum()
q8_2021['%'] = np.round(q8_2021['percentage'] * 100, 1)
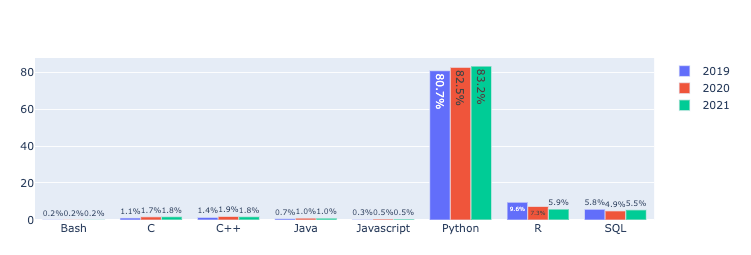
- 해당 데이터를 막대그래프로 시각화
fig = go.Figure()
fig.add_trace(go.Bar(x = q8_2019['Q8'],
y = q8_2019['%'],
name = "2019",
text = q8_2019['%'].astype(str) + "%",
textposition='auto'))
fig.add_trace(go.Bar(x = q8_2020['Q8'],
y = q8_2020['%'],
name = "2020",
text = q8_2020['%'].astype(str) + "%",
textposition='auto'))
fig.add_trace(go.Bar(x = q8_2021['Q8'],
y = q8_2021['%'],
name = "2021",
text = q8_2021['%'].astype(str) + "%",
textposition='auto'))시각화 결과 🎉
728x90
'Python > Data Visualization' 카테고리의 다른 글
| [연속형 변수 단일값 시각화] Univariate analysis of continuous variables (0) | 2023.08.22 |
|---|---|
| [구글 colab 데이터 시각화] 한글 폰트 설정 (0) | 2023.08.16 |
| [Kaggle 데이터 활용] 여러 개의 그래프 한번에 그리기(2) 심화 (0) | 2023.08.10 |
| [Kaggle 데이터 활용] 여러 개의 그래프 한번에 그리기(2) 기초 (0) | 2023.08.10 |
| [Plotly] Kaggle Survey Data 시각화 기초 (0) | 2023.08.10 |



