
🧑💻 코드 종합
(3)까지 진행한 결과를 종합하면 모델링 베이스 라인 코드는 다음과 같다.
이번 시간에는 3개의 모델 별로 K-fold 교차 검증을 수행하고, 그 결과 점수(MAE)의 평균값을 시각화하여 비교해본다.
이렇게 1차 베이스라인 모델링 코드를 마무리한다!
1. 라벨 인코딩
# 라벨 인코딩(sex)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
train['generated'] = 1
original['generated'] = 0
test['generated'] = 1
train.drop(columns = 'id', axis = 1, inplace = True)
train = pd.concat([train, original], axis = 0).reset_index(drop = True)
train['Sex'] = le.fit_transform(train['Sex'])
2. 변수 분리(독립변수, 종속변수)
# X, Y 변수 분리
X = train.drop(columns = 'Age', axis = 1)
Y = train['Age']
# id 컬럼 삭제 & test 데이터도 라벨인코딩
test_baseline = test.drop(columns = ['id'], axis = 1)
test_baseline['Sex'] = le.transform(test_baseline['Sex'])3. 모델별 MAE와 예측값을 담을 리스트 생성
# 결과 점수(MAE)와 예측값을 담을 리스트 생성 --->> 모델 개수 만큼
gb_cv_scores, gb_preds = list(), list()
hist_cv_scores, hist_preds = list(), list()
lgb_cv_scores, lgb_preds = list(), list()
xgb_cv_scores, xgb_preds = list(), list()
ens_cv_scores, ens_preds = list(), list()
4. k-fold 교차 검증 수행
# K-fold 생성
skf = KFold(n_splits = 10, random_state = 42, shuffle = True)
5. k-fold 마다 적용할 모델 생성 및 학습, 예측 종합
- 모델 작업은 코랩에서 수행했으며, 간단히 Gradient Boosting & Hist Gradient Boosting & XGBoosting 결과를 함께 보기로 했음
- 결과는 For 문을 한 번 돌 때마다 이렇게 나온다

for i, (train_ix, test_ix) in enumerate(skf.split(X, Y)):
X_train, X_test = X.iloc[train_ix], X.iloc[test_ix]
Y_train, Y_test = Y.iloc[train_ix], Y.iloc[test_ix]
print('---------------------------------------------------------------')
######################
## GradientBoosting ##
######################
gb_md = GradientBoostingRegressor(loss = 'absolute_error',
n_estimators = 1000,
max_depth = 8,
learning_rate = 0.01,
min_samples_split = 10,
min_samples_leaf = 20).fit(X_train, Y_train)
gb_pred_1 = gb_md.predict(X_test[X_test['generated'] == 1])
gb_pred_2 = gb_md.predict(test_baseline)
gb_score_fold = mean_absolute_error(Y_test[X_test['generated'] == 1], gb_pred_1)
gb_cv_scores.append(gb_score_fold)
gb_preds.append(gb_pred_2)
print('Fold', i, '==> GradientBoositng oof MAE is ==>', gb_score_fold)
##########################
## HistGradientBoosting ##
##########################
hist_md = HistGradientBoostingRegressor(loss = 'absolute_error',
l2_regularization = 0.01,
early_stopping = False,
learning_rate = 0.01,
max_iter = 1000,
max_depth = 15,
max_bins = 255,
min_samples_leaf = 70,
max_leaf_nodes = 115).fit(X_train, Y_train)
hist_pred_1 = hist_md.predict(X_test[X_test['generated'] == 1])
hist_pred_2 = hist_md.predict(test_baseline)
hist_score_fold = mean_absolute_error(Y_test[X_test['generated'] == 1], hist_pred_1)
hist_cv_scores.append(hist_score_fold)
hist_preds.append(hist_pred_2)
print('Fold', i, '==> HistGradient oof MAE is ==>', hist_score_fold)
#############
## XGBoost ##
#############
xgb_md = XGBRegressor(objective = 'reg:pseudohubererror',
tree_method = 'exact',
colsample_bytree = 0.9,
gamma = 0.65,
learning_rate = 0.01,
max_depth = 7,
min_child_weight = 20,
n_estimators = 1000).fit(X_train, Y_train)
xgb_pred_1 = xgb_md.predict(X_test[X_test['generated'] == 1])
xgb_pred_2 = xgb_md.predict(test_baseline)
xgb_score_fold = mean_absolute_error(Y_test[X_test['generated'] == 1], xgb_pred_1)
xgb_cv_scores.append(xgb_score_fold)
xgb_preds.append(xgb_pred_2)
print('Fold', i, '==> XGBoost oof MAE is ==>', xgb_score_fold)
6. 모델별 k-fold 수행 결과 MAE 평균
# 각 모델별 MAE 점수 평균내기
gb_cv_score = np.mean(gb_cv_scores)
hist_cv_score = np.mean(hist_cv_scores)
xgb_cv_score = np.mean(xgb_cv_scores)
# 모델별 결과를 데이터 프레임으로 저장
model_perf = pd.DataFrame({'Model':['GradientBoosting', 'HistGradient', 'XGBoost'],
'cv-score': [gb_cv_score, hist_cv_score, xgb_cv_score]})
# 위 데이터 프레임을 시각화하여 한눈에 확인
plt.figure(figsize = (8, 8))
ax = sns.barplot(y = 'Model', x ='cv-score', data = model_perf)
ax.bar_label(ax.containers[0]);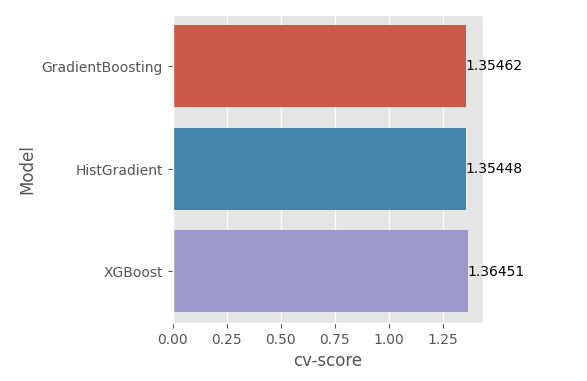
728x90
'Machine Learning > Case Study 👩🏻💻' 카테고리의 다른 글
| [🦀 게 나이 예측(6)] Baseline Modeling 2 (LAD Regression) (0) | 2023.09.26 |
|---|---|
| [🦀 게 나이 예측(5)] 모델 성능 개선을 위한 Feature Engineering (2) | 2023.09.25 |
| [🦀 게 나이 예측(3)] Baseline Modeling(Hist Gradient Boosting) (2) | 2023.09.24 |
| [🦀 게 나이 예측(2)] Baseline Modeling(Gradient Boosting) (0) | 2023.09.24 |
| [🦀 게 나이 예측(1)] 데이터 탐색 & EDA (0) | 2023.09.24 |



