
(4)~(5) 포스팅에서 진행한 모델링 코드를 참고하여 두 번째 베이스라인 코드를 작성한다.
피쳐 엔지니어링을 수행하고, 그 결과는 catboost 모델로 예측을 진행한다.
이외 다른 모델도 함께 사용하고 k-fold를 10회 진행하여 각 폴드마다 모델별 성과를 확인한다.
🚀 모델링 준비 : 변수 선택 & 인코딩
X = train.drop(columns = ['Age'], axis = 1)
Y = train['Age']
# train 독립변수에 대해 주요 파생변수 생성
X['Meat Yield'] = X['Shucked Weight'] / (X['Weight'] + X['Shell Weight'])
X['Shell Ratio'] = X['Shell Weight'] / X['Weight']
X['Weight_to_Shucked_Weight'] = X['Weight'] / X['Shucked Weight']
X['Viscera Ratio'] = X['Viscera Weight'] / X['Weight']
# test 데이터 정리 / 라벨 인코딩
test_baseline = test.drop(columns = ['id'], axis = 1)
test_baseline['Sex'] = le.transform(test_baseline['Sex'])
# test 독립변수도 동일 파생변수 생성
test_baseline['Meat Yield'] = test_baseline['Shucked Weight'] / (test_baseline['Weight'] + test_baseline['Shell Weight'])
test_baseline['Shell Ratio'] = test_baseline['Shell Weight'] / test_baseline['Weight']
test_baseline['Weight_to_Shucked_Weight'] = test_baseline['Weight'] / test_baseline['Shucked Weight']
test_baseline['Viscera Ratio'] = test_baseline['Viscera Weight'] / test_baseline['Weight']🚀 5개 모델별 & LAD 앙상블 결과 저장용 : MAE, 예측 결과 리스트 생성
aml_cv_scores, aml_preds = list(), list()
gb_cv_scores, gb_preds = list(), list()
hist_cv_scores, hist_preds = list(), list()
lgb_cv_scores, lgb_preds = list(), list()
xgb_cv_scores, xgb_preds = list(), list()
cat_cv_scores, cat_preds = list(), list()
ens_cv_scores_1, ens_preds_1 = list(), list()
ens_cv_scores_2, ens_preds_2 = list(), list()
ens_cv_scores_3, ens_preds_3 = list(), list()
ens_cv_scores_4, ens_preds_4 = list(), list()
🚀 K-fold 생성, 폴드별 모델링 수행 및 결과 확인
- 지난 모델링에서와 같이 모델링 코드를 동일하게 작성
- 5가지 모델 사용 : Gradient Boosting, Hist Gradeint, LightBGM, XGBoost, CatBoost
- 여기에 파라미터를 조정한 4가지 LAD 회귀 모델을 추가로 사용
skf = KFold(n_splits = 10, random_state = 42, shuffle = True)
for i, (train_ix, test_ix) in enumerate (skf.split(X, Y)):
X_train, X_test = X.iloc[train_ix], X.iloc[test_ix]
Y_train, Y_test = Y.iloc[train_ix], Y.iloc[test_ix]
print('---------------------------------------------------------------')
######################
## GradientBoosting ##
######################
gb_features = ['Sex',
'Length',
'Diameter',
'Height',
'Weight',
'Shucked Weight',
'Viscera Weight',
'Shell Weight',
'generated']
# 모델링에 사용할 주요 피쳐만 뽑아 저장
X_train_gb = X_train[gb_features]
X_test_gb = X_test[gb_features]
test_baseline_gb = test_baseline[gb_features]
gb_md = GradientBoostingRegressor(loss = 'absolute_error',
n_estimators = 1000,
max_depth = 8,
learning_rate = 0.01,
min_samples_split = 10,
min_samples_leaf = 20,
random_state = 42)
gb_md.fit(X_train_gb, Y_train)
gb_pred_1 = gb_md.predict(X_test_gb[X_test_gb['generated'] == 1])
gb_pred_2 = gb_md.predict(test_baseline_gb)
gb_score_fold = mean_absolute_error(Y_test[X_test_gb['generated'] == 1], gb_pred_1)
gb_cv_scores.append(gb_score_fold)
gb_preds.append(gb_pred_2)
print('Fold', i, '==> GradientBoositng oof MAE is ==>', gb_score_fold)
##########################
## HistGradientBoosting ##
##########################
hist_md = HistGradientBoostingRegressor(loss = 'absolute_error',
l2_regularization = 0.01,
early_stopping = False,
learning_rate = 0.01,
max_iter = 1000,
max_depth = 15,
max_bins = 255,
min_samples_leaf = 70,
max_leaf_nodes = 115,
random_state = 42).fit(X_train, Y_train)
hist_pred_1 = hist_md.predict(X_test[X_test['generated'] == 1])
hist_pred_2 = hist_md.predict(test_baseline)
hist_score_fold = mean_absolute_error(Y_test[X_test['generated'] == 1], hist_pred_1)
hist_cv_scores.append(hist_score_fold)
hist_preds.append(hist_pred_2)
print('Fold', i, '==> HistGradient oof MAE is ==>', hist_score_fold)
##############
## LightGBM ##
##############
lgb_md = LGBMRegressor(objective = 'mae',
n_estimators = 1000,
max_depth = 15,
learning_rate = 0.01,
num_leaves = 105,
reg_alpha = 8,
reg_lambda = 3,
subsample = 0.6,
colsample_bytree = 0.8,
random_state = 42).fit(X_train, Y_train)
lgb_pred_1 = lgb_md.predict(X_test[X_test['generated'] == 1])
lgb_pred_2 = lgb_md.predict(test_baseline)
lgb_score_fold = mean_absolute_error(Y_test[X_test['generated'] == 1], lgb_pred_1)
lgb_cv_scores.append(lgb_score_fold)
lgb_preds.append(lgb_pred_2)
print('Fold', i, '==> LightGBM oof MAE is ==>', lgb_score_fold)
#############
## XGBoost ##
#############
xgb_md = XGBRegressor(objective = 'reg:pseudohubererror',
tree_method = 'hist',
colsample_bytree = 0.9,
gamma = 0.65,
learning_rate = 0.01,
max_depth = 7,
min_child_weight = 20,
n_estimators = 1500,
subsample = 0.7,
random_state = 42).fit(X_train_gb, Y_train)
xgb_pred_1 = xgb_md.predict(X_test_gb[X_test_gb['generated'] == 1])
xgb_pred_2 = xgb_md.predict(test_baseline_gb)
xgb_score_fold = mean_absolute_error(Y_test[X_test_gb['generated'] == 1], xgb_pred_1)
xgb_cv_scores.append(xgb_score_fold)
xgb_preds.append(xgb_pred_2)
print('Fold', i, '==> XGBoost oof MAE is ==>', xgb_score_fold)
##############
## CatBoost ##
##############
cat_features = ['Sex',
'Length',
'Diameter',
'Height',
'Weight',
'Shucked Weight',
'Viscera Weight',
'Shell Weight',
'generated',
'Meat Yield',
'Shell Ratio',
'Weight_to_Shucked_Weight']
X_train_cat = X_train[cat_features]
X_test_cat = X_test[cat_features]
test_baseline_cat = test_baseline[cat_features]
cat_md = CatBoostRegressor(loss_function = 'MAE',
iterations = 1000,
learning_rate = 0.08,
depth = 10,
random_strength = 0.2,
bagging_temperature = 0.7,
border_count = 254,
l2_leaf_reg = 0.001,
verbose = False,
grow_policy = 'Lossguide',
task_type = 'CPU',
random_state = 42).fit(X_train_cat, Y_train)
cat_pred_1 = cat_md.predict(X_test_cat[X_test_cat['generated'] == 1])
cat_pred_2 = cat_md.predict(test_baseline_cat)
cat_score_fold = mean_absolute_error(Y_test[X_test_cat['generated'] == 1], cat_pred_1)
cat_cv_scores.append(cat_score_fold)
cat_preds.append(cat_pred_2)
print('Fold', i, '==> CatBoost oof MAE is ==>', cat_score_fold)[ 🧑💻 LAD 회귀 ] for 문 안에 이어지는 코드이지만, 정리를 위해 아래 따로 작성
LAD 회귀란?
* Least Absolute Deviation으로, 이상치에 덜 민감하고 데이터 분포가 정규분포를 따르지 않을 때 유용하다
* 잔차의 절대값 합을 최소화하여 모델을 적합시키는 방법이다
* 회귀 모델의 적합성 평가를 위해 주로 평균 절대 오차(MAE)를 사용한다.
- x : 5개 모델의 예측값을 소수점 첫째짜리에서 반올림하여, 데이터 프레임을 생성
- y : test용 train 데이터의 종속변수
- fit_intercept : 회귀모델에서 상수항을 학습할 지 여부를 지정(상수항은 회귀 직선이 원점을 통과하는지 여부를 결정)
- True : 기본값으로 상수항을 포함하여 회귀 직선을 학습함. 일반적인 상황에서 사용되며 데이터가 원점을 중심으로 분포하지 않는 경우 유용하다.
- False : 모델이 상수항을 무시하고 회귀 직선을 원점으로 통과하도록 강제한다. 이렇게 설정하면 데이터가 원점을 중심으로 데이터가 분포할 것을 가정한다.
- fit_intercept를 조절하여 모델 편향을 조절하고, 데이터와 모델 간 적합도를 더 잘 조절할 수 있다.
- positive : 회귀 모델에서 예측값이 양수로 제한되어야 하는지 여부.
- True : 모델 예측값이 양수로 제한(예측값은 0 또는 양의 값만 가질 수 있음)
- False : 모델 예측값에 제한을 두지 않음
- 가격 예측과 같이 예측값이 양수로만 제한되어야 하는 문제에서 모델 유효성을 높일 수 있음
##################
## LAD Ensemble ##
##################
x = pd.DataFrame({'GBC': np.round(gb_pred_1.tolist()), 'hist': np.round(hist_pred_1.tolist()),
'lgb': np.round(lgb_pred_1.tolist()), 'xgb': np.round(xgb_pred_1.tolist()),
'cat': np.round(cat_pred_1.tolist())})
y = Y_test[X_test['generated'] == 1]
x_test = pd.DataFrame({'GBC': np.round(gb_pred_2.tolist()), 'hist': np.round(hist_pred_2.tolist()),
'lgb': np.round(lgb_pred_2.tolist()), 'xgb': np.round(xgb_pred_2.tolist()),
'cat': np.round(cat_pred_2.tolist())})
lad_md_1 = LADRegression(fit_intercept = True, positive = False).fit(x, y)
lad_md_2 = LADRegression(fit_intercept = True, positive = True).fit(x, y)
lad_md_3 = LADRegression(fit_intercept = False, positive = True).fit(x, y)
lad_md_4 = LADRegression(fit_intercept = False, positive = False).fit(x, y)
lad_pred_1 = lad_md_1.predict(x)
lad_pred_2 = lad_md_2.predict(x)
lad_pred_3 = lad_md_3.predict(x)
lad_pred_4 = lad_md_4.predict(x)
lad_pred_test_1 = lad_md_1.predict(x_test)
lad_pred_test_2 = lad_md_2.predict(x_test)
lad_pred_test_3 = lad_md_3.predict(x_test)
lad_pred_test_4 = lad_md_4.predict(x_test)
ens_score_1 = mean_absolute_error(y, lad_pred_1)
ens_cv_scores_1.append(ens_score_1)
ens_preds_1.append(lad_pred_test_1)
ens_score_2 = mean_absolute_error(y, lad_pred_2)
ens_cv_scores_2.append(ens_score_2)
ens_preds_2.append(lad_pred_test_2)
ens_score_3 = mean_absolute_error(y, lad_pred_3)
ens_cv_scores_3.append(ens_score_3)
ens_preds_3.append(lad_pred_test_3)
ens_score_4 = mean_absolute_error(y, lad_pred_4)
ens_cv_scores_4.append(ens_score_4)
ens_preds_4.append(lad_pred_test_4)
print('Fold', i, '==> LAD Model 1 ensemble oof MAE is ==>', ens_score_1)
print('Fold', i, '==> LAD Model 2 ensemble oof MAE is ==>', ens_score_2)
print('Fold', i, '==> LAD Model 3 ensemble oof MAE is ==>', ens_score_3)
print('Fold', i, '==> LAD Model 4 ensemble oof MAE is ==>', ens_score_4)
👉 결과 확인

🚀 폴드별 결과(MAE) 평균내어 데이터프레임으로 확인, 시각화
gb_cv_score = np.mean(gb_cv_scores)
hist_cv_score = np.mean(hist_cv_scores)
lgb_cv_score = np.mean(lgb_cv_scores)
xgb_cv_score = np.mean(xgb_cv_scores)
cat_cv_score = np.mean(cat_cv_scores)
ens_cv_score_1 = np.mean(ens_cv_scores_1)
ens_cv_score_2 = np.mean(ens_cv_scores_2)
ens_cv_score_3 = np.mean(ens_cv_scores_3)
ens_cv_score_4 = np.mean(ens_cv_scores_4)
model_perf = pd.DataFrame({'Model': ['GradientBoosting', 'HistGradient' ,'LightGBM', 'XGBoost', 'CatBoost',
'LDA Model 1',
'LDA Model 2',
'LDA Model 3',
'LDA Model 4'],
'cv-score': [gb_cv_score, hist_cv_score, lgb_cv_score, xgb_cv_score, cat_cv_score,
ens_cv_score_1,
ens_cv_score_2,
ens_cv_score_3,
ens_cv_score_4]})
plt.figure(figsize = (8, 8))
ax = sns.barplot(y = 'Model', x = 'cv-score', data = model_perf)
ax.bar_label(ax.containers[0]);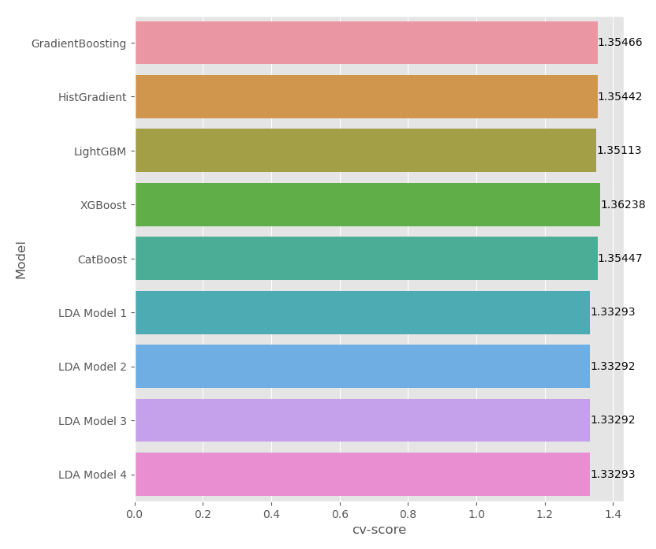
728x90
'Machine Learning > Case Study 👩🏻💻' 카테고리의 다른 글
| [공모전 수상작 스터디] 일회용품 쓰레기 감소를 위한,다회용기 비즈니스 모델 개발 (서울시 빅데이터 캠퍼스) (1) | 2023.10.05 |
|---|---|
| [kaggle] 피마 인디언 당뇨병 예측 (0) | 2023.09.29 |
| [🦀 게 나이 예측(5)] 모델 성능 개선을 위한 Feature Engineering (2) | 2023.09.25 |
| [🦀 게 나이 예측(4)] Baseline Modeling(여러 모델 결과를 종합, 비교) (0) | 2023.09.25 |
| [🦀 게 나이 예측(3)] Baseline Modeling(Hist Gradient Boosting) (2) | 2023.09.24 |



