
1. 타겟 값 분포 & 주요 컬럼의 분포 확인하기
- 데이터의 타겟 값(대출 연체 여부)를 확인한다. >> 각 값(0, 1)의 개수와 비율
app_train['TARGET'].value_counts()
app_train['TARGET'].value_counts() / 307511 * 100
- 타겟의 null 값 확인
apps['TARGET'].value_counts(dropna=False)
- 주요 컬럼의 분포를 히스토그램으로 확인한다
sns.distplot(app_train['AMT_INCOME_TOTAL'])
plt.hist(app_train['AMT_INCOME_TOTAL'])
- 일부 필터도 적용해본다 (예를 들어, 소득이 1,000,000 이하인 선에서 주요 컬럼의 분포)
cond_1 = app_train['AMT_INCOME_TOTAL'] < 1000000
app_train[cond_1]['AMT_INCOME_TOTAL'].hist()
- 분포를 표현할 때 distplot을 사용해도 좋다.
특히, 연속형 변수의 히스토그램을 그릴 때 kde로 직관적인 확인이 가능하다
sns.distplot(app_train[app_train['AMT_INCOME_TOTAL'] < 1000000]['AMT_INCOME_TOTAL'])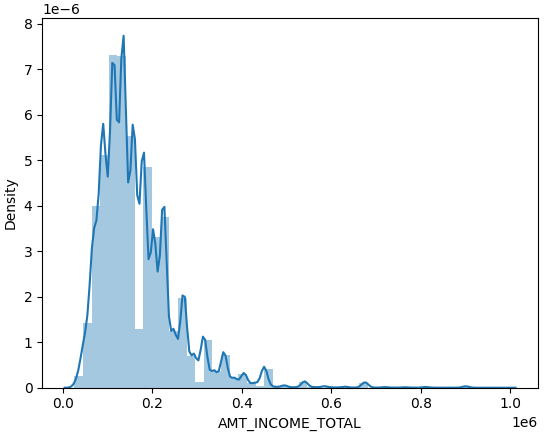
2. 타겟 값에 따른 주요 컬럼의 분포 확인하기(함수)
- seaborn의 Distplot과 violinplot의 분포로 비교 시각화
- 함수로 정의하여 한눈에 확인하기
def show_column_hist_by_target(df, column, is_amt = False):
# 조건 지정(타겟이 1, 0 일때)
cond1 = (app_train['TARGET'] == 1)
cond0 = (app_train['TARGET'] == 0)
# 그래프 그릴 준비(사이즈 지정)
fig, axs = plt.subplots(figsize = (12, 4), nrows = 1, ncols = 2, squeeze = False)
# is_amt가 True이면, < 500000 조건으로 필터링
cond_amt = True
if is_amt:
cond_amt = df[column] < 500000
sns.violinplot(x = 'TARGET', y = column, data = df[cond_amt], ax = axs[0][0])
sns.distplot(df[cond0 & cond_amt][column], ax = axs[0][1], label = '0', color = 'blue')
sns.distplot(df[cond1 & cond_amt][column], ax = axs[0][1], label = '1', color = 'red')
show_column_hist_by_target(app_train, 'AMT_INCOME_TOTAL', is_amt = True)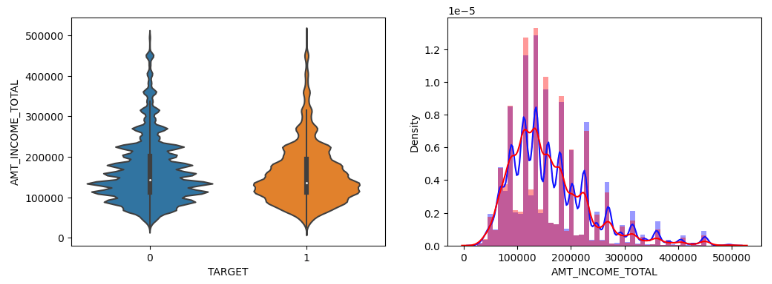
3. 카테고리형 피쳐들의 Label Encoding
- 특정 데이터 타입의 피쳐들만 리스트로 불러오기
object_columns = apps.dtypes[apps.dtypes == 'object'].index.tolist()
- pandas 의 factorize()를 이용 >> [0]이, 인코딩한 결괏값
- 단, 주의할 점은 한번에 한 컬럼만 가능하므로, 반복문을 이용해야함.
for column in object_columns:
apps[column] = pd.factorize(apps[column])[0]
# apps.info()로 object 형이 없는지 확인
4. LGBM Classifier 로 학습 수행
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
train_x, valid_x, train_y, valid_y = train_test_split(ftr_app, target_app, test_size = 0.3, random_state = 2020)
train_x.shape, valid_x.shape
clf = LGBMClassifier(
n_jobs=-1, #모든 병력을 다 쓰겠다.
n_estimators=1000, #1000번의 Week_learner 만들겠다.
learning_rate=0.02,
num_leaves=32, #마지막 리프노드 수
subsample=0.8,
max_depth=12,
silent=-1,
verbose=-1
)
clf.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)], eval_metric= 'auc', verbose= 100, early_stopping_rounds= 50)
- Feature importance 시각화
from lightgbm import plot_importance
plot_importance(clf, figsize=(16, 32))
- 예측 확률 값 확인
preds = clf.predict_proba(apps_test.drop(['SK_ID_CURR'], axis = 1))[:, 1]
app_test['TARGET'] = preds728x90
'Machine Learning > Case Study 👩🏻💻' 카테고리의 다른 글
| [Home Credit Default Risk] 3.주요 Feature들에 대한 feature engineering (0) | 2023.10.31 |
|---|---|
| [Home Credit Default Risk] 2. 주요 Feature에 대한 EDA (0) | 2023.10.30 |
| [BG/NBD] 고객 거래 행동 예측 모델 (2) | 2023.10.10 |
| [Kaggle] 이커머스 데이터 분석 7 (CRM Analytics 🛍️🛒) (1) | 2023.10.10 |
| [Kaggle] 이커머스 데이터 분석 6 (CRM Analytics 🛍️🛒) (0) | 2023.10.08 |



