
1. 결측치 처리
- 앞선 EDA와 분포 시각화, 베이스라인 모델링의 feature Importance를 토대로 주요 피쳐를 선정
- 각 피쳐의 null 값 확인
app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].isnull().sum()
# dropna = false 로 null 값 개수까지 확인
app_train['EXT_SOURCE_1'].value_counts(dropna=False)
app_train['EXT_SOURCE_2'].value_counts(dropna=False)
app_train['EXT_SOURCE_3'].value_counts(dropna=False)
- 주요 피쳐들의 평균/최대/최소/표준편차를 확인
# EXT_SOURCE_X 피처들의 평균/최대/최소/표준편차 확인
print('### mean ###\n', app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].mean())
print('### max ###\n',app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].max())
print('### min ###\n',app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].min())
print('### std ###\n',app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].std())
2. 피쳐 가공(결측치 처리) 전, Train, test 데이터셋 결합
- Train 데이터의 가공 내용을 test 셋에 동일하게 적용하는것이 번거로우니
apps = pd.concat([app_train, app_test])
print(apps.shape)
- row 별로 3개 피쳐를 결합하여 평균과 표준편차를 신규 생성
- 결합하는 컬럼을 리스트로 묶고, .mean(axis=1) 로 행별 값 산출
apps['APPS_EXT_SOURCE_MEAN'] = apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].mean(axis = 1)
apps['APPS_EXT_SOURCE_STD'] = apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].std(axis = 1)
- 생성된 컬럼 확인 후, Nan 값을 처리
- 이 경우, 표준편차의 결측치가 하나라도 있으면 생성된 컬럼 값이 Nan이 됨 >> 전체 표준편차의 평균으로 채우기
apps.iloc[:, -2:].head()
apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'APPS_EXT_SOURCE_MEAN', 'APPS_EXT_SOURCE_STD']].head()
apps['APPS_EXT_SOURCE_STD'] = apps['APPS_EXT_SOURCE_STD'].fillna(apps['APPS_EXT_SOURCE_STD'].mean())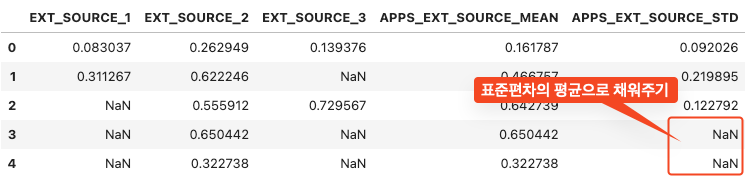
3. Feature 가공
- 주요 피쳐의 특성을 고려하여 다양하게 조합을 생각해본다.
- 예시는 다음과 같다
# 대출금액 대비 월 대출지급액 등 비율
apps['APPS_ANNUITY_CREDIT_RATIO'] = apps['AMT_ANNUITY']/apps['AMT_CREDIT']
apps['APPS_GOODS_CREDIT_RATIO'] = apps['AMT_GOODS_PRICE'] / apps['AMT_CREDIT']
apps['APPS_CREDIT_GOODS_DIFF'] = apps['AMT_CREDIT'] - apps['AMT_GOODS_PRICE']
# AMT_INCOME_TOTAL 비율로 대출 금액 관련 피처 가공
apps['APPS_ANNUITY_INCOME_RATIO'] = apps['AMT_ANNUITY']/apps['AMT_INCOME_TOTAL']
apps['APPS_CREDIT_INCOME_RATIO'] = apps['AMT_CREDIT']/apps['AMT_INCOME_TOTAL']
apps['APPS_GOODS_INCOME_RATIO'] = apps['AMT_GOODS_PRICE']/apps['AMT_INCOME_TOTAL']
# 가족수를 고려한 가처분 소득 피처 가공
apps['APPS_CNT_FAM_INCOME_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['CNT_FAM_MEMBERS']
# DAYS_BIRTH, DAYS_EMPLOYED 비율로 소득/자산 관련 Feature 가공.
apps['APPS_EMPLOYED_BIRTH_RATIO'] = apps['DAYS_EMPLOYED']/apps['DAYS_BIRTH']
apps['APPS_INCOME_EMPLOYED_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['DAYS_EMPLOYED']
apps['APPS_INCOME_BIRTH_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['DAYS_BIRTH']
apps['APPS_CAR_BIRTH_RATIO'] = apps['OWN_CAR_AGE'] / apps['DAYS_BIRTH']
apps['APPS_CAR_EMPLOYED_RATIO'] = apps['OWN_CAR_AGE'] / apps['DAYS_EMPLOYED']
4. 두 번째 학습 모델 생성
- 이전과 동일하게 데이터레이블 인코딩 진행
- null 값은 LightGBM 내부에서 처리하도록 특별한 변경 안함
object_columns = apps.dtypes[apps.dtypes == 'object'].index.tolist()
for column in object_columns:
apps[column] = pd.factorize(apps[column])[0]
# Train, Test 데이터를 target 값 기준으로 분리
apps_train = apps[~apps['TARGET'].isnull()]
apps_test = apps[apps['TARGET'].isnull()]
# 학습/검증 데이터 셋 분리 후 모델 학습
from sklearn.model_selection import train_test_split
ftr_app = apps_train.drop(['SK_ID_CURR', 'TARGET'], axis=1)
target_app = app_train['TARGET']
train_x, valid_x, train_y, valid_y = train_test_split(ftr_app, target_app, test_size=0.3, random_state=2020)
from lightgbm import LGBMClassifier
clf = LGBMClassifier(
n_jobs=-1,
n_estimators=1000,
learning_rate=0.02,
num_leaves=32,
subsample=0.8,
max_depth=12,
silent=-1,
verbose=-1
)
clf.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)], eval_metric= 'auc', verbose= 100,
early_stopping_rounds= 100)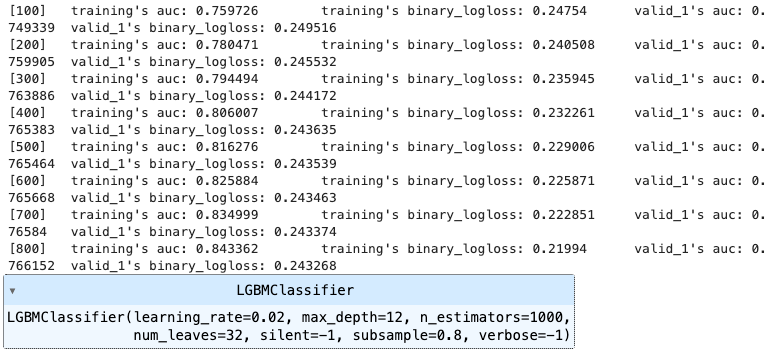
728x90
'Machine Learning > Case Study 👩🏻💻' 카테고리의 다른 글
| [Home Credit Default Risk] 5. 이전 대출이력 데이터 EDA, FE 수행(수정중) (0) | 2023.11.15 |
|---|---|
| [Home Credit Default Risk] 4. 이전 대출 이력 데이터 EDA 및 병합 (1) | 2023.11.09 |
| [Home Credit Default Risk] 2. 주요 Feature에 대한 EDA (0) | 2023.10.30 |
| [Home Credit Default Risk] 1. 데이터 분포 시각화, 라벨 인코딩 (0) | 2023.10.30 |
| [BG/NBD] 고객 거래 행동 예측 모델 (2) | 2023.10.10 |



