
1. 이전 application(메인데이터) 의 Feature Engineering 함수 복사
def get_apps_processed(apps):
# EXT_SOURCE_X FEATURE 가공
apps['APPS_EXT_SOURCE_MEAN'] = apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].mean(axis=1)
apps['APPS_EXT_SOURCE_STD'] = apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].std(axis=1)
apps['APPS_EXT_SOURCE_STD'] = apps['APPS_EXT_SOURCE_STD'].fillna(apps['APPS_EXT_SOURCE_STD'].mean())
# AMT_CREDIT 비율로 Feature 가공
apps['APPS_ANNUITY_CREDIT_RATIO'] = apps['AMT_ANNUITY']/apps['AMT_CREDIT']
apps['APPS_GOODS_CREDIT_RATIO'] = apps['AMT_GOODS_PRICE']/apps['AMT_CREDIT']
# AMT_INCOME_TOTAL 비율로 Feature 가공
apps['APPS_ANNUITY_INCOME_RATIO'] = apps['AMT_ANNUITY']/apps['AMT_INCOME_TOTAL']
apps['APPS_CREDIT_INCOME_RATIO'] = apps['AMT_CREDIT']/apps['AMT_INCOME_TOTAL']
apps['APPS_GOODS_INCOME_RATIO'] = apps['AMT_GOODS_PRICE']/apps['AMT_INCOME_TOTAL']
apps['APPS_CNT_FAM_INCOME_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['CNT_FAM_MEMBERS']
# DAYS_BIRTH, DAYS_EMPLOYED 비율로 Feature 가공
apps['APPS_EMPLOYED_BIRTH_RATIO'] = apps['DAYS_EMPLOYED']/apps['DAYS_BIRTH']
apps['APPS_INCOME_EMPLOYED_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['DAYS_EMPLOYED']
apps['APPS_INCOME_BIRTH_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['DAYS_BIRTH']
apps['APPS_CAR_BIRTH_RATIO'] = apps['OWN_CAR_AGE'] / apps['DAYS_BIRTH']
apps['APPS_CAR_EMPLOYED_RATIO'] = apps['OWN_CAR_AGE'] / apps['DAYS_EMPLOYED']
return apps
▶︎ 이전 대출 데이터(prev) 메인데이터(apps)를 merge
prev_app_outer = prev.merge(apps['SK_ID_CURR'], on = 'SK_ID_CURR', how = 'outer', indicator = True)
👉 merge 할 때 indicator = True 로 조인 후, 누락된 집합을 확인할 수 있음.
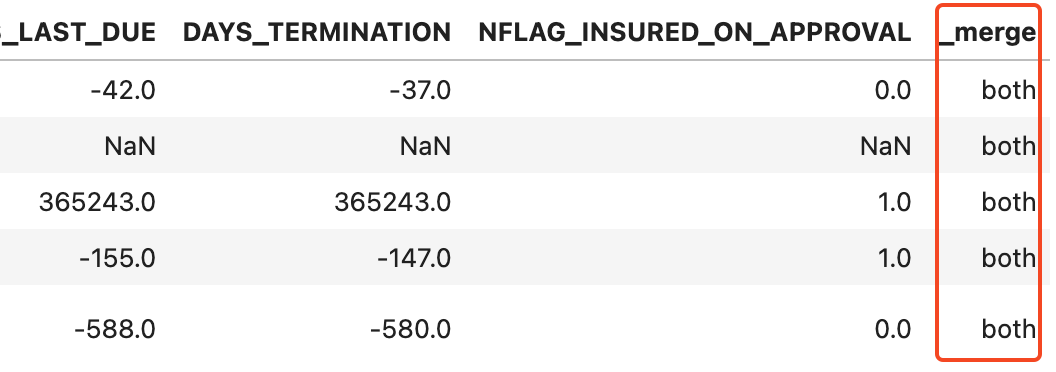
prev_app_outer['_merge'].value_counts()
👉 _merge 컬럼을 value_counts() 하여 각각 어떻게 조인되어있는지 확인

2. 주요 컬럼 EDA
▶︎ apps(메인데이터)의 ID별로, 이전 대출 이력 건수를 확인
- groupby, boxplot
prev.groupby('SK_ID_CURR')['SK_ID_PREV'].count()

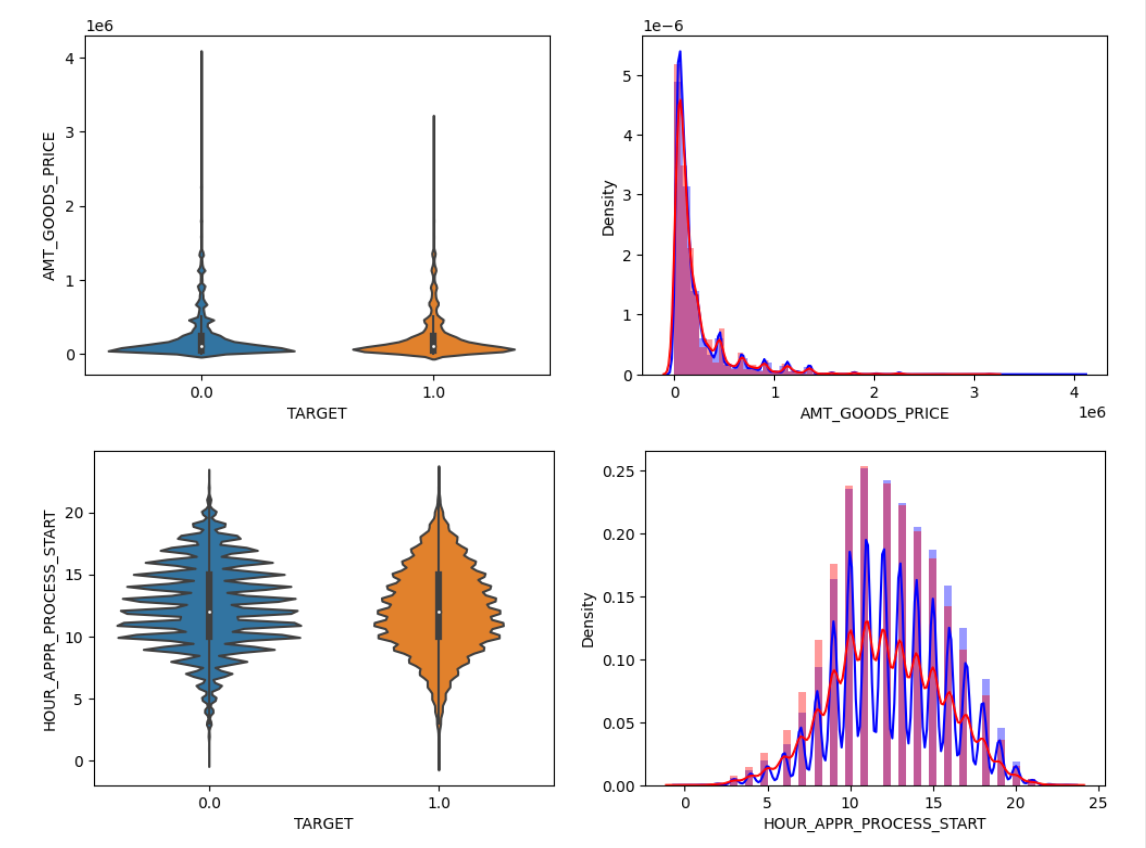
▶︎ 숫자형 피쳐들의 분포 확인(히스토그램) / Target 유형에 따라
- 메인데이터의 ID, Target 값과 prev(과거 대출이력) 데이터 merge
app_prev= prev.merge(app_train[['SK_ID_CURR', 'TARGET']], on = 'SK_ID_CURR', how = 'left')
app_prev.shape
- Target 값에 따라 히스토그램을 그리는 함수
def show_hist_by_target(df, columns):
cond_1 = (df['TARGET'] == 1)
cond_0 = (df['TARGET'] == 0)
for column in columns:
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(12, 4), squeeze=False)
sns.violinplot(x='TARGET', y=column, data=df, ax=axs[0][0] )
sns.distplot(df[cond_0][column], ax=axs[0][1], label='0', color='blue')
sns.distplot(df[cond_1][column], ax=axs[0][1], label='1', color='red')
- 숫자형 피쳐들의 컬럼명 분리
- 기존 컬럼들중 ID, target 컬럼을 제외하고 리스트에 저장
num_columns = app_prev.dtypes[app_prev.dtypes != 'object'].index.tolist()
num_columns = [column for column in num_columns if column not in ['SK_ID_CURR', 'SK_ID_PREV', 'TARGET']]
- 히스토그램 시각화 및 결과 해석
show_hist_by_target(app_prev, num_columns)
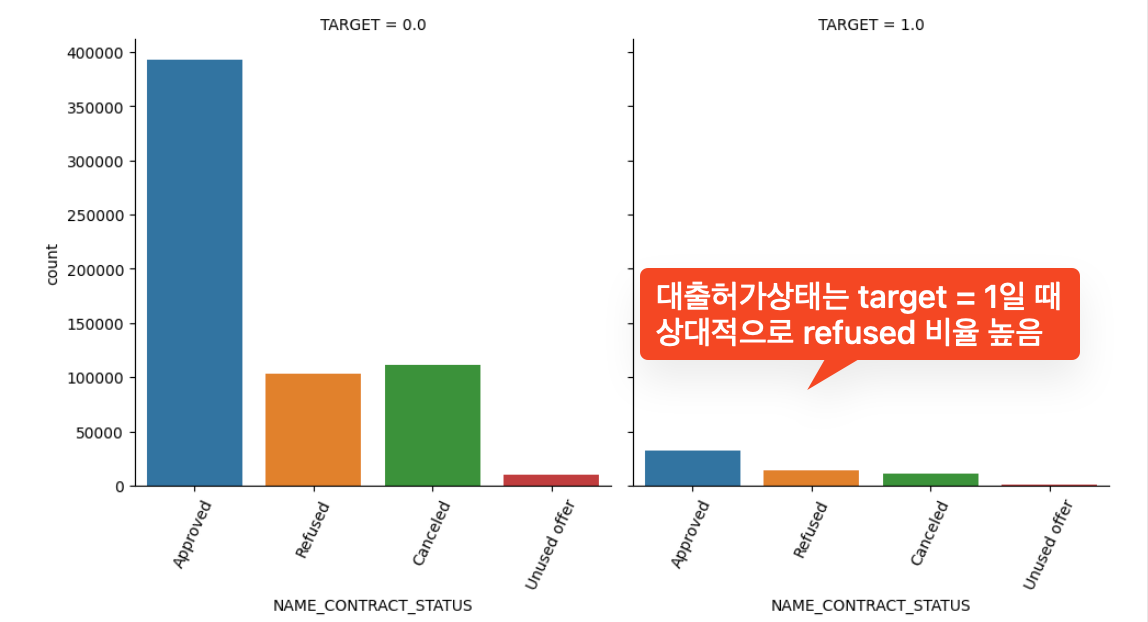
▶︎ 카테고리형 피쳐들의 분포 확인(히스토그램) / Target 유형에 따라
object_columns = app_prev.dtypes[app_prev.dtypes=='object'].index.tolist()
object_columns
- 카테고리형 컬럼은 📊 catplot을 사용!!
def show_category_by_target(df, columns):
for column in columns:
chart = sns.catplot(x=column, col="TARGET", data=df, kind="count")
chart.set_xticklabels(rotation=65)
show_category_by_target(app_prev, object_columns)
▶︎ groupby 로 피쳐 확인하기
- agg_dict 를 정의하고, groupby 결과에 한번에 적용
agg_dict = {
# 기존 컬럼.
'SK_ID_CURR':['count'],
'AMT_CREDIT':['mean', 'max', 'sum'],
'AMT_ANNUITY':['mean', 'max', 'sum'],
'AMT_APPLICATION':['mean', 'max', 'sum'],
'AMT_DOWN_PAYMENT':['mean', 'max', 'sum'],
'AMT_GOODS_PRICE':['mean', 'max', 'sum']
}
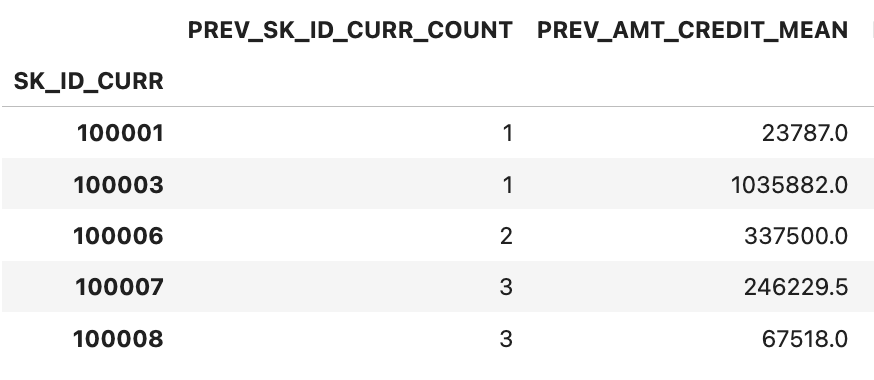
prev_group = prev.groupby('SK_ID_CURR')
prev_amt_agg = prev_group.agg(agg_dict)
prev_amt_agg.head() #결과는 멀티레벨 인덱스(컬럼)
- 멀티 인덱스 컬럼변경 >> 언더바('_')로 연결해서 컬럼명 깔끔하게 정리
# 컬럼이 멀티인덱스인거 확인
prev_amt_agg.columns
prev_amt_agg.columns =
['PREV_' + ('_').join(column).upper() for column in prev_amt_agg.columns]
prev_amt_agg.head()
▶︎ prev 피쳐 가공
# 대출 신청 금액과 실제 대출액/대출 상품금액 차이 및 비율
prev['PREV_CREDIT_DIFF'] = prev['AMT_APPLICATION'] - prev['AMT_CREDIT']
prev['PREV_GOODS_DIFF'] = prev['AMT_APPLICATION'] - prev['AMT_GOODS_PRICE']
prev['PREV_CREDIT_APPL_RATIO'] = prev['AMT_CREDIT']/prev['AMT_APPLICATION']
prev['PREV_ANNUITY_APPL_RATIO'] = prev['AMT_ANNUITY']/prev['AMT_APPLICATION']
prev['PREV_GOODS_APPL_RATIO'] = prev['AMT_GOODS_PRICE']/prev['AMT_APPLICATION']
▶︎ 이상치를 Null로 대체
prev['DAYS_FIRST_DRAWING'].replace(365243, np.nan, inplace = True)
prev['DAYS_FIRST_DUE'].replace(365243, np.nan, inplace= True)
prev['DAYS_LAST_DUE_1ST_VERSION'].replace(365243, np.nan, inplace= True)
prev['DAYS_LAST_DUE'].replace(365243, np.nan, inplace= True)
prev['DAYS_TERMINATION'].replace(365243, np.nan, inplace= True)
# 첫번째 만기일과 마지막 만기일까지의 기간
prev['PREV_DAYS_LAST_DUE_DIFF'] = prev['DAYS_LAST_DUE_1ST_VERSION'] - prev['DAYS_LAST_DUE']
▶︎ 이자율에 null 값이 많으므로, 직접 컬럼 생성
# 월 납부액 * 횟수 =>> 총 대출상환액
all_pay = prev['AMT_ANNUITY'] * prev['CNT_PAYMENT']
# 이자올 = (대출상환액/대출액 -1) / 대출상환횟수
prev['PREV_INTERESTS_RATE'] = (all_pay / prev['AMT_CREDIT'] -1)/prev['CNT_PAYMENT']
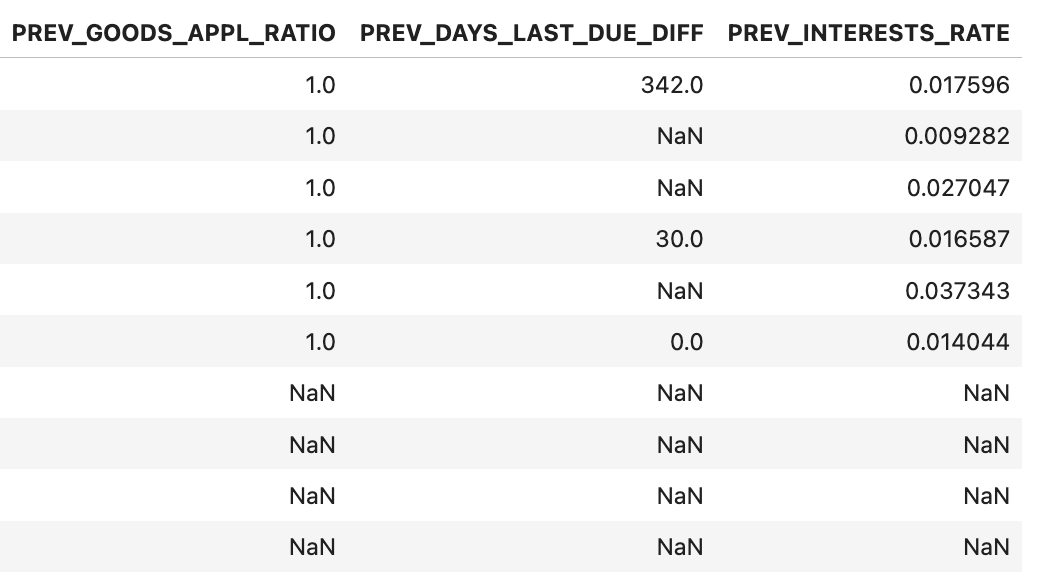
=>>> 생성된 컬럼 확인
prev.iloc[:, -7:].head(10)
▶︎ ID 기준으로 (기존)대출 상태가 refused 인 경우의 건수 및 과거 대출 건 대비 비율 구하기
- 🧐 메인 데이터에서 대출상태가 '거절'인 경우에는 과거 대출 건 수와 어떤 관련이 있는지 알아보자
# 조건
cond_refused = (prev['NAME_CONTRACT_STATUS'] == 'Refused')
# 조건 적용
prev_refused = prev[cond_refused]
# 확인
prev_refused.shape, prev.shape
##((138377, 44), (798432, 44))
- 조건을 적용한 데이터프레임의 refused 건수 도출
- groupby, count
- pd.DataFrame()으로 groupby 결과를 확인
prev_refused_agg = prev_refused.groupby('SK_ID_CURR')['SK_ID_CURR'].count()
prev_refused_agg.shape, prev_amt_agg.shape
##((79325,), (281965, 39))
pd.DataFrame(prev_refused_agg) # reset_index()가 안된 상태

- reset_index()로 인덱스와 컬럼명 중복 풀어주기
- name을 지정하여 컬럼명을 변경
prev_refused_agg = prev_refused_agg.reset_index(name = 'PREV_REFUSED_COUNT')
prev_refused_agg.head()
▶︎ 위에서 만든 prev_amt_agg 컬럼과 결합
prev_amt_agg = prev_amt_agg.reset_index()
prev_amt_refused_agg = prev_amt_agg.merge(prev_refused_agg, on = 'SK_ID_CURR', how = 'left')
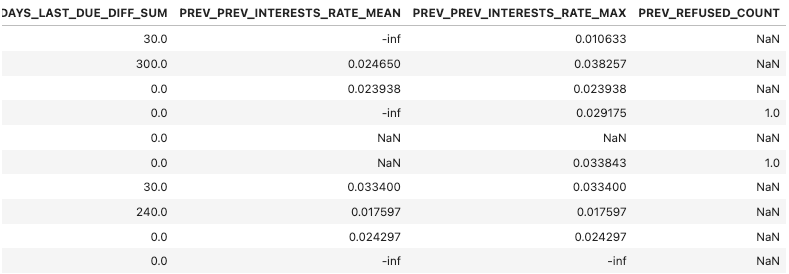
- 결측치 처리 :
# 결측치 개수까지 확인
prev_amt_refused_agg['PREV_REFUSED_COUNT'].value_counts(dropna = False)
# 결측치를 0으로 채움
prev_amt_refused_agg = prev_amt_refused_agg.fillna(0)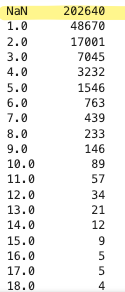
- 과거 대출 건 수 대비 대출 거절 건 수
👉 거절 대출 건 수 / 과거 대출 건수 >> 비율 산출
prev_amt_refused_agg['PREV_REFUSED_RATIO'] = prev_amt_refused_agg['PREV_REFUSED_COUNT'] / prev_amt_refused_agg['PREV_SK_ID_CURR_COUNT']
prev_amt_refused_agg.head(10)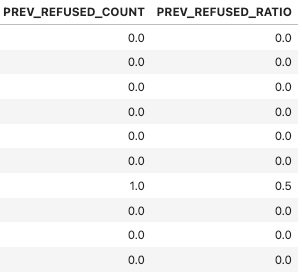
[TIP ❤️] Case When + groupby 단계를 수행하는 다른 방법 (unstack 사용)
예) 대출 신청 상태가 '승인', '거절'인 경우에 각 ID 별로 몇 건인지 확인
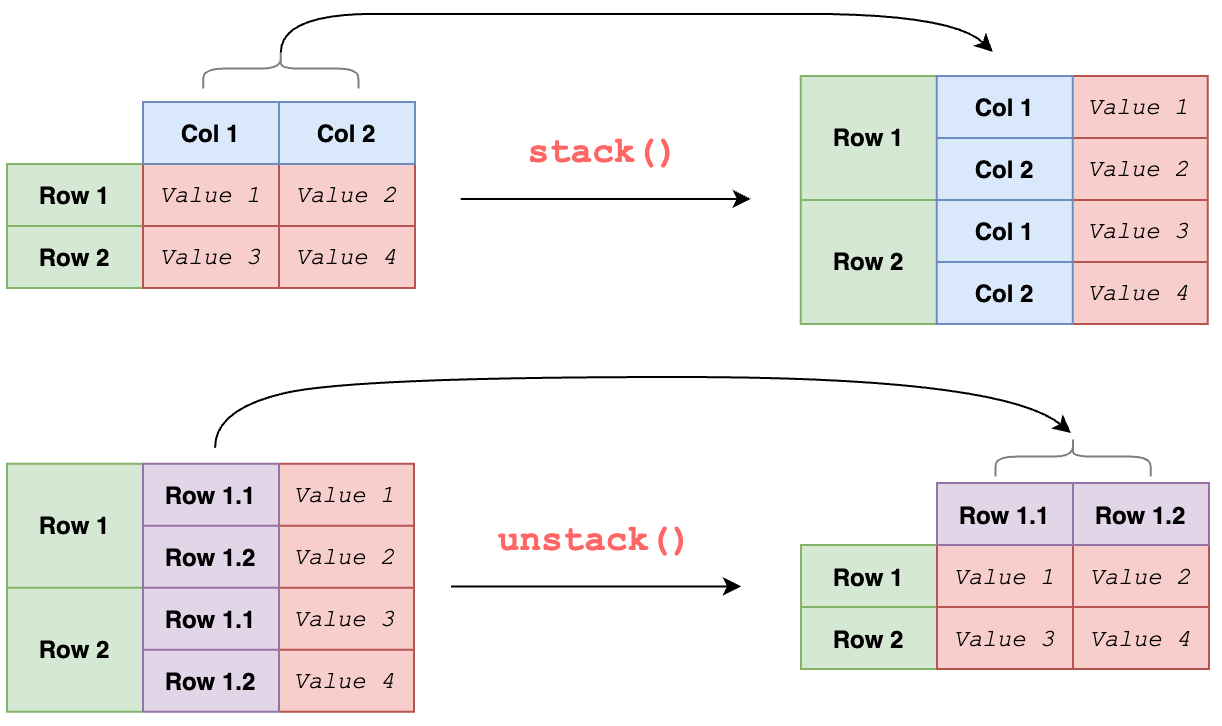
- 아래과 같이 isin()에 대출상태를 지정하고, groupby()에 두 개 컬럼을 넣어 각 경우의 수를 셀 수 있음
- groupby 할 때, 마지막에 unstack()을 해줘야 함
prev_refused_appr_group = prev[prev['NAME_CONTRACT_STATUS'].isin(['Approved', 'Refused'])].
groupby(['SK_ID_CURR', 'NAME_CONTRACT_STATUS'])
prev_refused_appr_agg = prev_refused_appr_group['SK_ID_CURR'].count().unstack()
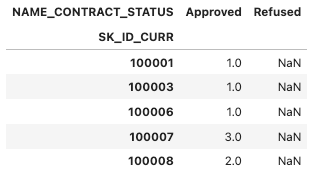
# 결측치 채우고 컬럼명 변경
prev_refused_appr_agg = prev_refused_appr_agg.fillna(0)
prev_refused_appr_agg.columns = ['PREV_APPROVED_COUNT', 'PREV_REFUSED_COUNT']
# 리셋인덱스로 정리
prev_refused_appr_agg = prev_refused_appr_agg.reset_index()
prev_refused_appr_agg.head(3)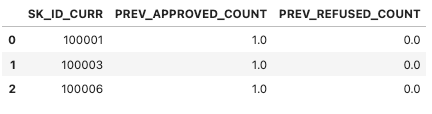
- prev_amt_agg와 조인 후 데이터 가공
prev_agg = prev_amt_agg.merge(prev_refused_appr_agg, on = 'SK_ID_CURR', how = 'left')
# SK_ID_CURR별 과거 대출건수 대비 APPROVED_COUNT 및 REFUSED_COUNT 비율 생성.
prev_agg['PREV_REFUSED_RATIO'] = prev_agg['PREV_REFUSED_COUNT']/prev_agg['PREV_SK_ID_CURR_COUNT']
prev_agg['PREV_APPROVED_RATIO'] = prev_agg['PREV_APPROVED_COUNT']/prev_agg['PREV_SK_ID_CURR_COUNT']
# 'PREV_REFUSED_COUNT', 'PREV_APPROVED_COUNT' 컬럼 drop
prev_agg = prev_agg.drop(['PREV_REFUSED_COUNT', 'PREV_APPROVED_COUNT'], axis=1)
# prev_amt_agg와 prev_refused_appr_agg INDEX인 SK_ID_CURR이 조인 후 정식 컬럼으로 생성됨.
prev_agg.head(3)

728x90
'Machine Learning > Case Study 👩🏻💻' 카테고리의 다른 글
| [Pandas] 파이썬으로 이커머스 데이터 A/B test 결과 해석 (feat. 통계 검정) (1) | 2024.01.30 |
|---|---|
| [Home Credit Default Risk] 5. 이전 대출이력 데이터 EDA, FE 수행(수정중) (0) | 2023.11.15 |
| [Home Credit Default Risk] 3.주요 Feature들에 대한 feature engineering (0) | 2023.10.31 |
| [Home Credit Default Risk] 2. 주요 Feature에 대한 EDA (0) | 2023.10.30 |
| [Home Credit Default Risk] 1. 데이터 분포 시각화, 라벨 인코딩 (0) | 2023.10.30 |



