
1. 연속형 피쳐의 분포 시각화(Target 값에 따라)
- 함수를 이용하여, 컬럼별로 target값이 0, 1일 때 시각화하기
- violinplot, distplot 사용
- 결과를 보며, target 에 따라 유의미한 차이가 나는 피쳐 확인 >> 피쳐 중요도 파악
👉 연령대가 낮은(또는 직장 경력이 적은), 소액 대출 건에서 연체 비중이 높아 보임
def show_hist_by_target(df, columns):
# 타겟 값에 따른 조건 지정
cond_1 = (df['TARGET'] == 1)
cond_0 = (df['TARGET'] == 0)
# 그래프 그리기
for column in columns:
print('column name: ', column) #확인용
fig, axs = plt.subplots(figsize = (12, 4), nrows=1, ncols=2, squeeze=False)
sns.violinplot(x = 'TARGET', y = column, data = df, ax = axs[0][0])
sns.distplot(df[cond_1][column], label = '1', color = 'red', ax = axs[0][1]) #시리즈로 넣어줘야함
sns.distplot(df[cond_0][column], label = '0', color = 'blue', ax = axs[0][1])
show_hist_by_target(app_train, columns)
2. 명목형 피쳐의 분포 시각화(Target 값에 따라)
- countplot을 이용하여, 명목형 피쳐의 히스토그램을 표현
# object 데이터 컬럼만 리스트로
object_columns = app_train.dtypes[app_train.dtypes =='object'].index.to_list()
# 시각화 함수
def show_count_by_target(df, columns):
cond_1 = (df['TARGET'] == 1)
cond_0 = (df['TARGET'] == 0)
for column in columns:
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(18, 4), squeeze=False)
# countplot을 이용하여 category값의 histogram 표현
chart0 = sns.countplot(df[cond_0][column], ax=axs[0][0])
# x축의 tick label들이 값 유형이 많으므로 45도로 회전하여 표현
chart0.set_xticklabels(chart0.get_xticklabels(), rotation=45)
chart1 = sns.countplot(df[cond_1][column], ax=axs[0][1])
chart1.set_xticklabels(chart1.get_xticklabels(), rotation=45)
show_count_by_target(app_train, object_columns)
- catplot()을 이용하면 다음과 같이 target 값에 따라 피쳐 값의 분포를 동일한 y 선상에서 비교 가능
# y 대신, col을 써주는 것 유의
sns.catplot(x = 'CODE_GENDER', col = 'TARGET', data = app_train, kind = 'count')
# 시각화 함수 정의
def show_category_by_target(df, columns):
for column in columns:
print('col name: ', column)
chart = sns.catplot(x = column, col = 'TARGET', data = df, kind = 'count')
chart.set_xticklabels(rotation = 65)
show_category_by_target(app_train, object_columns)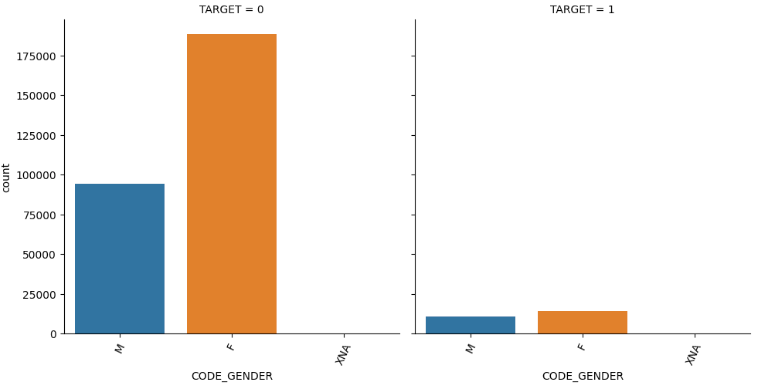
- 결과를 확인하여, 일부 값을 데이터프레임으로 확인
👉 예를 들어, 바로 위 이미지를 보면 대출 횟수 대비 연체 비율이 남성이 여성 보다 높아 보이므로 이를 확인
cond_1 = (app_train['TARGET'] == 1)
cond_0 = (app_train['TARGET'] == 0)
print(app_train['CODE_GENDER'].value_counts() / app_train.shape[0])
print(app_train[cond_1]['CODE_GENDER'].value_counts() / app_train[cond_1].shape[0])
print(app_train[cond_0]['CODE_GENDER'].value_counts() / app_train[cond_0].shape[0])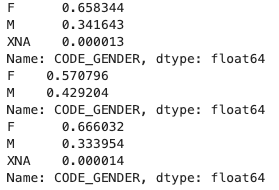
3. Target 과 주요 컬럼의 상관관계 분석
- 주요 컬럼을 추출하고, corr()으로 상관계수를 도출
- 히트맵을 통해 확인
corr_columns = ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH', 'AMT_CREDIT', 'AMT_ANNUITY', 'AMT_GOODS_PRICE',
'DAYS_EMPLOYED','DAYS_ID_PUBLISH', 'DAYS_REGISTRATION', 'DAYS_LAST_PHONE_CHANGE', 'AMT_INCOME_TOTAL', 'TARGET']
col_corr = app_train[corr_columns].corr()
col_corr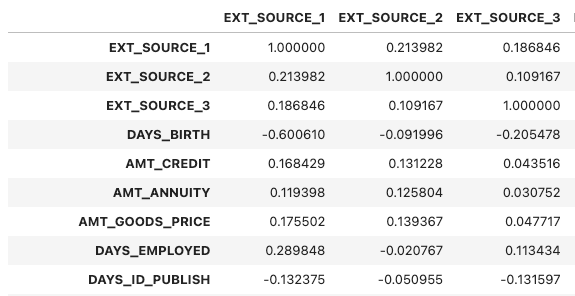
plt.figure(figsize = (9, 9))
sns.heatmap(col_corr, annot = True)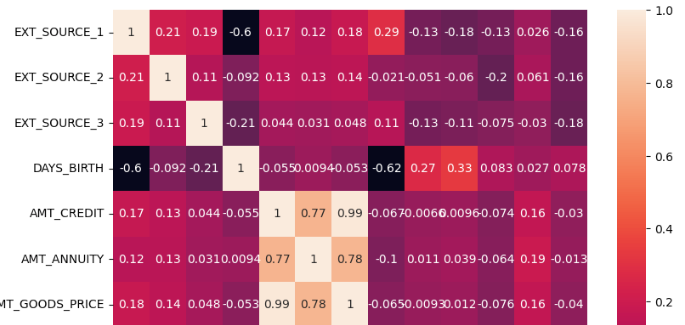
4. 이상치 확인 및 처리
- 위의 컬럼별 분포 시각화 결과를 보며, 비상식적인 이상치(예를 들면, 근속기간 3만년..)를 처리
# 이상치 데이터 직접 확인
## 365243이 매우 많음. 약 1000년치에 해당하는 날짜
app_train['DAYS_EMPLOYED'].value_counts()
## CODE_GENDER의 경우 XNA가 4건 정도인데, 많지 않으므로 그대로 유지
app_train['CODE_GENDER'].value_counts()
# replace로 대체
app_train['DAYS_EMPLOYED'] = app_train['DAYS_EMPLOYED'].replace(365243, np.nan)
# 결과 확인
app_train['DAYS_EMPLOYED'].value_counts(dropna = False)
728x90
'Machine Learning > Case Study 👩🏻💻' 카테고리의 다른 글
| [Home Credit Default Risk] 4. 이전 대출 이력 데이터 EDA 및 병합 (1) | 2023.11.09 |
|---|---|
| [Home Credit Default Risk] 3.주요 Feature들에 대한 feature engineering (0) | 2023.10.31 |
| [Home Credit Default Risk] 1. 데이터 분포 시각화, 라벨 인코딩 (0) | 2023.10.30 |
| [BG/NBD] 고객 거래 행동 예측 모델 (2) | 2023.10.10 |
| [Kaggle] 이커머스 데이터 분석 7 (CRM Analytics 🛍️🛒) (1) | 2023.10.10 |



