최종 결과물
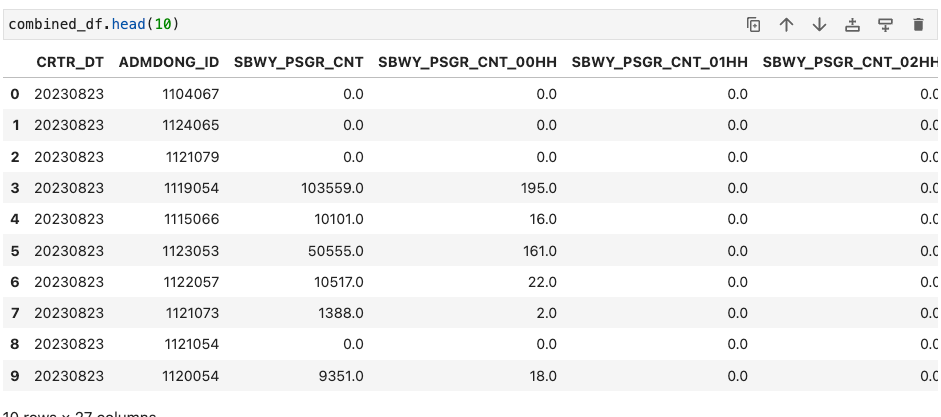
API 데이터 불러오기
- 공공데이터 포털의 API는 1000페이지씩 데이터를 따로 가져올 수 있다.
- 반복문을 사용하여 1000페이지 단위로 url을 수정하며 데이터를 가져온다
- requests.get(url) 로 Json 데이터 가져오기
- json 데이터에서 필요한 부분만 get
- data.get('가져올 키값1', { }).get('가져올 키값2', [ ])
- { } 와 [ ] 는 데이터 형태에 따라 일치하는 것을 기입
- get 한 값을 Item에 저장
- 반복문 종료를 위해, item 이 없으면 break 되도록 함
- item을 dataframe으로 변환하고, 변환된 df를 data_frames 리스트에 저장
- 최종적으로 data_frames에 들어있는 데이터프레임을 concat
- concat한 최종 데이터 프레임을 return
base_url = "http://openapi.seoul.go.kr:8088/인증키/json/tpssSubwayPassenger/"
items_per_page = 1000
total_pages = None
data_frames = []
for i in range(1, 1001): # Adjust the range according to your needs
start_page = (i - 1) * items_per_page + 1
end_page = i * items_per_page
url = f"{base_url}{start_page}/{end_page}/"
response = requests.get(url)
data = response.json()
# Check if the retrieved data is empty
items = data.get('tpssSubwayPassenger', {}).get('row', [])
if not items:
break
df = pd.DataFrame(items)
data_frames.append(df)
# Concatenate all DataFrames into a single DataFrame
combined_df = pd.concat(data_frames, ignore_index=True)
# Now you have a single DataFrame containing data from all pages
print(combined_df)결과 확인

행정동(ADMDONG_ID) 데이터 병합해서 살펴보기
- 행정동 데이터를 가져와서, 어느 지역의 데이터인지 살펴봐야한다
- 서울시 읍면동 마스터 정보 가져오기 > combined_dong에 저장
base_url = "http://openapi.seoul.go.kr:8088/57756f69527273303830644c4b4c6f/json/districtEmd/"
items_per_page = 1000
total_pages = None
data_frames = []
for i in range(1, 1001): # Adjust the range according to your needs
start_page = (i - 1) * items_per_page + 1
end_page = i * items_per_page
url = f"{base_url}{start_page}/{end_page}/"
response = requests.get(url)
data = response.json()
# Check if the retrieved data is empty
items = data.get('districtEmd', {}).get('row', [])
if not items:
break
df = pd.DataFrame(items)
data_frames.append(df)
# Concatenate all DataFrames into a single DataFrame
combined_dong = pd.concat(data_frames, ignore_index=True)
# Now you have a single DataFrame containing data from all pages
print(combined_dong)
행정동 데이터와 지하철 이용자 수 데이터 합치기
- 행정동 아이디를 기준으로, 데이터를 조인
- 이때, 지하철 데이터를 기준으로 left join 되도록 한다
subway_dong = pd.merge(combined_df, combined_dong, on = 'ADMDONG_ID', how = 'left')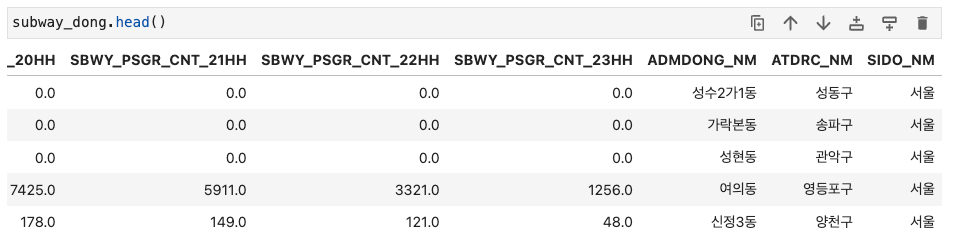
행정동 아이디 컬럼 삭제 & 시간 컬럼명 변경
subway_dong.drop('ADMDONG_ID', axis = 1, inplace = True)
# 컬럼명 변경
subway_dong = subway_dong.rename(columns = {'SBWY_PSGR_CNT_00HH' : '00시', 'SBWY_PSGR_CNT_01HH' : '01시', 'SBWY_PSGR_CNT_02HH' : '02시',
'SBWY_PSGR_CNT_03HH': '03시', 'SBWY_PSGR_CNT_04HH' :'04시', 'SBWY_PSGR_CNT_05HH':'05시',
'SBWY_PSGR_CNT_06HH' : '06시', 'SBWY_PSGR_CNT_07HH' : '07시', 'SBWY_PSGR_CNT_08HH' : '08시',
'SBWY_PSGR_CNT_09HH': '09시', 'SBWY_PSGR_CNT_10HH' :'10시', 'SBWY_PSGR_CNT_11HH':'11시', 'SBWY_PSGR_CNT_12HH':'12시',
'SBWY_PSGR_CNT_13HH' : '13시', 'SBWY_PSGR_CNT_14HH' : '14시', 'SBWY_PSGR_CNT_15HH' : '15시',
'SBWY_PSGR_CNT_16HH': '16시', 'SBWY_PSGR_CNT_17HH' :'17시', 'SBWY_PSGR_CNT_18HH':'18시',
'SBWY_PSGR_CNT_19HH' : '19시', 'SBWY_PSGR_CNT_20HH' : '20시', 'SBWY_PSGR_CNT_21HH' : '21시',
'SBWY_PSGR_CNT_22HH': '22시', 'SBWY_PSGR_CNT_23HH' :'23시', 'SBWY_PSGR_CNT_24HH':'24시'})

서울 데이터이므로, SIDO_NM 컬럼 삭제
# 서울 값만 있는지 간단히 체크 후,
subway_dong['SIDO_NM'].unique()
# 해당 컬럼 삭제
subway_dong.drop('SIDO_NM', axis =1, inplace = True)
데이터타입 확인 후, 날짜 컬럼을 datetime으로
👉 날짜에 해당하는 CRTR_DT : object(문자형)
subway_dong.info()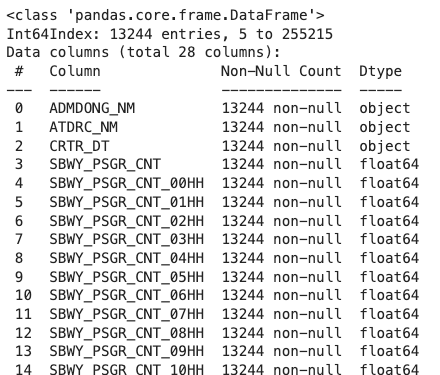
👉 CRTR_DT를 datetime으로
subway_dong['CRTR_DT'] = pd.to_datetime(subway_dong['CRTR_DT'])
subway_dong.info()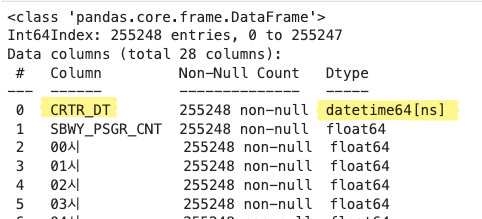
👉 CRTR_DT에서 연도, 월, 일 추출해보기
# 연월일 추출
def extract_date_info(df, date_column_name):
df['연도'] = df[date_column_name].dt.year
df['월'] = df[date_column_name].dt.month
df['일'] = df[date_column_name].dt.day
return df
subway_gangnam = extract_date_info(subway_gangnam, 'CRTR_DT')
subway_gangnam.head(1)
# subway_gangnam.info()
👉 강남구 데이터만 추출
subway_gangnam = subway_dong[subway_dong['ATDRC_NM'] == '강남구']
subway_gangnam.head()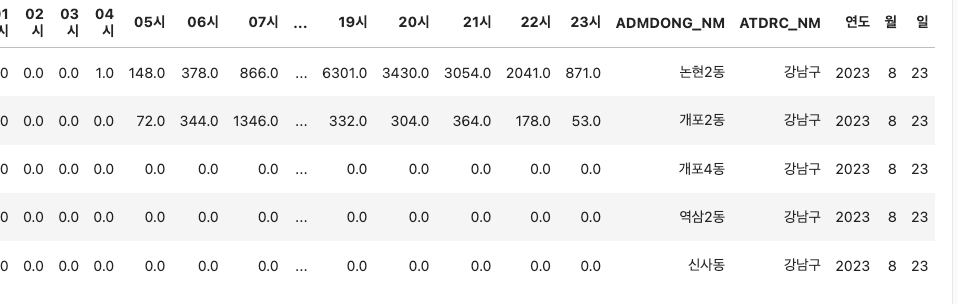
👉 컬럼 순서 변경(보기 좋게!)
cols_list = subway_gangnam.columns[-7:].tolist() + subway_gangnam.columns[:-7].tolist()
subway_gangnam = subway_gangnam[cols_list]
subway_gangnam.head()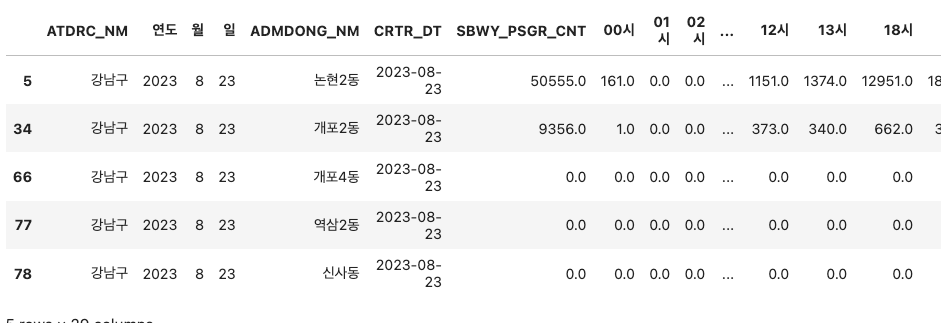
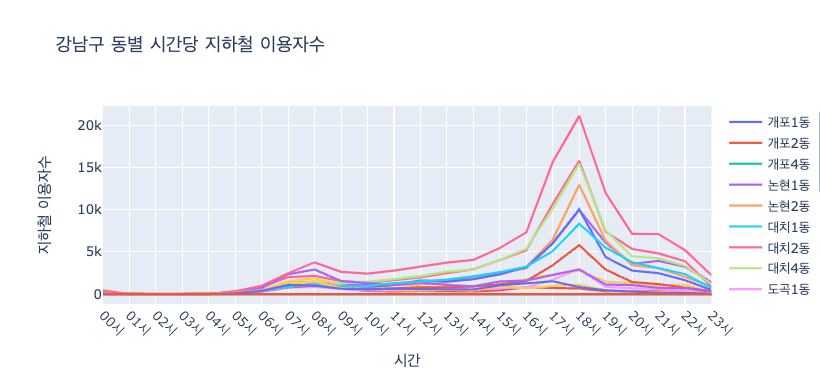
시각화
- 2023년, 강남구 내 행정동별 지하철 사용자 수 데이터
grouped_df = subway_gangnam[subway_gangnam['연도'] == 2023].groupby('ADMDONG_NM')
import plotly.graph_objects as go
fig = go.Figure()
for dong, df in grouped_df:
fig.add_trace(go.Scatter(x = df.columns[7:], y = df.iloc[0, 7:], name = dong))
fig.update_layout(title = '강남구 동별 시간당 지하철 이용자수',
xaxis_title = '시간',
yaxis_title = '지하철 이용자수')
fig.update_xaxes(tickangle=45)
fig.show()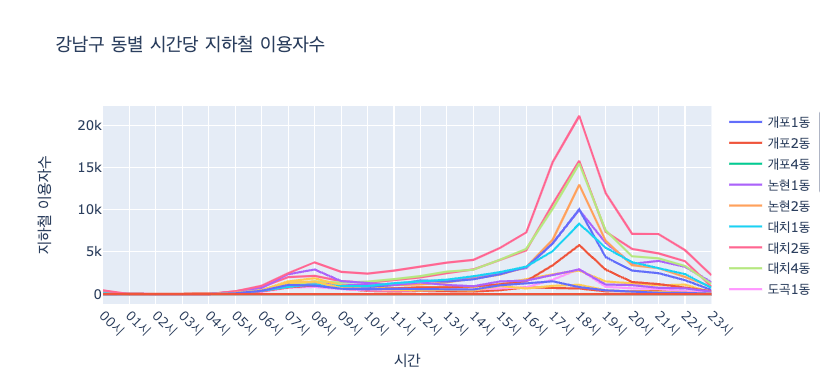
728x90
'Projects > 🏪 Convenience Store Location Analysis' 카테고리의 다른 글
| [Mini Project] 4. 대중교통(지하철) 위치 데이터 전처리 (0) | 2023.09.08 |
|---|---|
| [Mini Project] 3. 상권(분기별/상권별/시간대별 매출액) 데이터 전처리 (0) | 2023.09.08 |
| [Mini Project] 2. 데이터 탐색과 전처리 (0) | 2023.09.08 |
| [Mini Project] 1. 주제 선정과 데이터 수집 (0) | 2023.09.08 |
| [pandas 응용실습] 강남구 주차 현황 시각화 (0) | 2023.08.28 |



